一个含有语言过滤和智能去重功能的 nhentai 本子下载器
- nhentai 本身提供的下载方式只有种子下载,速度堪忧,且需要登录
- 为了批量下载喜欢的题材或画师的本子
该项目的定位是下载器,而不是爬虫,我不推荐也不赞同使用该程序进行过量的下载,并且过量下载会导致出现验证码问题而无法继续下载
到 releases 下载对应平台(只有部分)的可执行文件
- Windows
改名为nhder.exe并扔到C:\Windows\System32中 - Linux
改名为nhder并扔到/usr/local/bin中
当然你也可以就直接放在非系统环境变量的目录中,只是调用麻烦点
版本更新的话重复上述操作即可
首先安装 Nodejs
- Windows
打开官网 => 下载右边的“最新发布版” => 安装一路确定 - Linux
# Ubuntu curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash - sudo apt-get install -y nodejs # Debian curl -sL https://deb.nodesource.com/setup_10.x | bash - apt-get install -y nodejs # Centos curl -sL https://rpm.nodesource.com/setup_10.x | bash - yum install nodejs -y
然后执行命令
npm i -g nhder如果是 Windows 则在命令提示符或 PowerShell 中键入命令(后续同理)
版本更新的话也是执行上面这句命令即可
nhder --setting将看到以下界面
nhder options
[1] Download path F:\nhentai # 下载目录
[2] Download thread 16 # 下载线程
[3] Analysis thread 5 # 解析线程
[4] Download timeout 30s # 下载超时
[5] Deduplication Enable # 去重功能
[6] Languages filter chinese, japanese # 语言过滤
[7] Proxy Disable # 代理设置
[0] Exit # 退出
Press a key [1...7 / 0]:
输入数字可进入对应设置项,首次下载之前必须设置下载目录
- 下载目录
请注意相对路径与绝对路径的区别,不过不用担心,输入完路径后会显示绝对路径以方便你检查
目录无需手动建立,下载图片的时候会自动建立 - 下载线程
即同时下载的图片数,默认为8,最小为1,最大为32
下载图片时最左侧的一列实际上就是线程编号 - 解析线程
解析多页结果时请求 API 的线程数,默认为5,最小为1,最大为10
如果解析时出现 503 错误请尝试调小此值 - 下载超时
如果这么多秒之后一张图还没被下载完则算作超时,出现超时或网络错误现象会自动重试,默认值为30秒
下载图片时如果线程编号是黄色标记的就代表此次是重试
重试超过10次则视作下载失败,此时线程编号会以红色标记,程序终止 - 去重
开启了以后,在批量下载一个分类或搜索页面中的多个本子时会过滤掉重复的本子(通常是因为一个本子有多种翻译语言) - 语言过滤
批量下载时将忽略不在该语言集合中的语言的本子
如果开启去重功能,则会按语言集合的先后顺序作为优先级进行过滤,例如语言过滤为chinese,japanese,如果页面中同时包含同一个本子的日语原本与汉化本,则优先下载汉化本,而如果顺序颠倒japanese,chinese则下载日语原本
常见的语言字串有 chinese japanese english - 使用代理
支持使用 HTTP 或 SOCKS 代理,即可以使用小飞机
输入格式为<协议>://[用户名:密码@]<IP>:<端口>,例如:http://user:passwd@127.0.0.1:1080socks://127.0.0.1:1080(如果你使用小飞机则直接填这个,除非你改过本地端口)
nhder https://nhentai.net/g/255771/
# 或
nhder 255771# 默认会下载第一页
nhder https://nhentai.net/tag/lolicon/
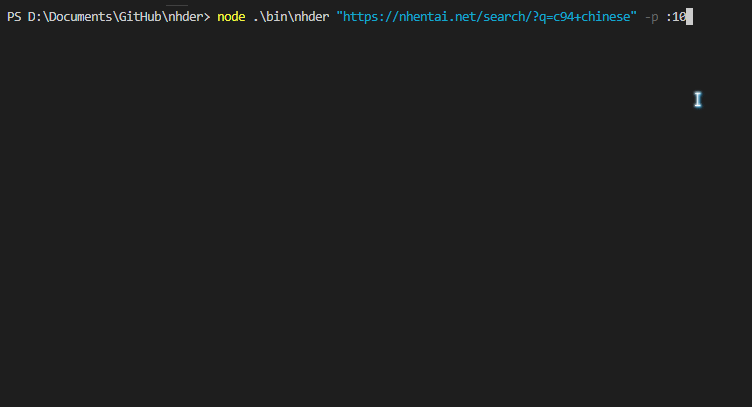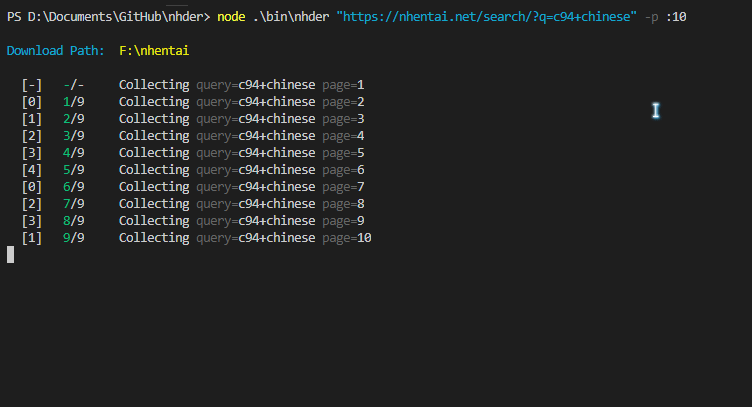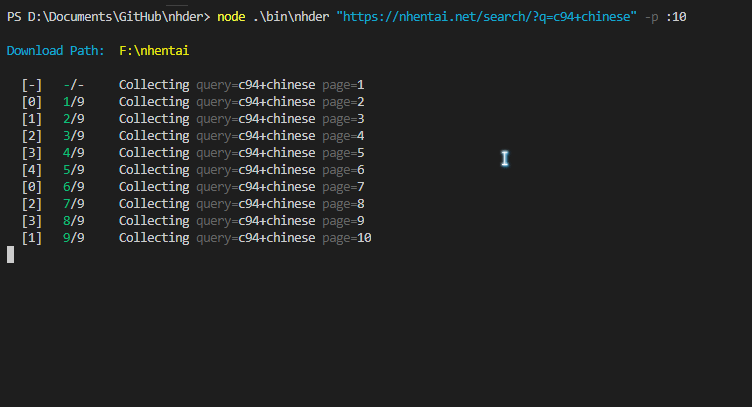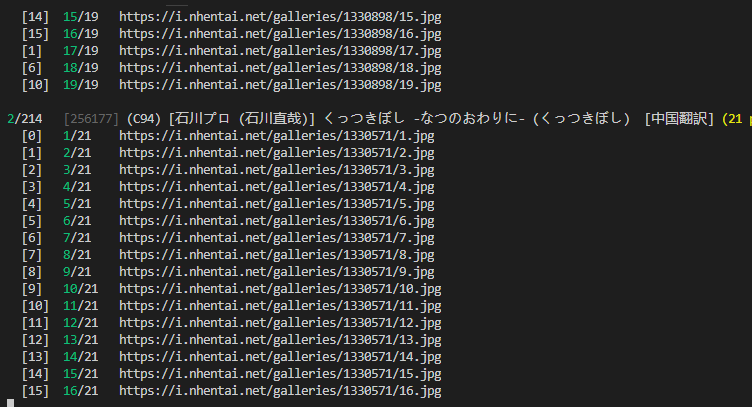
nhder https://nhentai.net/search/?q=c94+chinese
# 如果你复制的链接是翻过页的,那么就会下载你翻到的那页,即由 page 字段来决定
# 注意,如果链接中带有 & 符号,在某些命令行中可能会出现错误,建议使用英文双引号包裹链接
nhder https://nhentai.net/tag/lolicon/?page=2
nhder "https://nhentai.net/search/?q=c94+chinese&page=2"另外,你也可以使用-p参数来对这种可翻页的页面指定下载全部或部分页面,此时会忽略链接中的 page 字段
格式为-p start:end,表示下载 [start, end] 页数范围的所有本子;start 与 end 可以不填,此时默认 start 为 1,end 为最大页数;-p与-p :是一样的,但如果你直接使用-p,则必须将其放到命令的最末端
# 下载 10~20页
nhder https://nhentai.net/tag/lolicon/ -p 10:20
# 下载 1~15页
nhder https://nhentai.net/tag/lolicon/ -p :15
# 下载 30页~最后
nhder https://nhentai.net/tag/lolicon/ -p 30:
# 下载全部
nhder https://nhentai.net/tag/lolicon/ -p可以填入多个 URL 或 gid,程序会顺次下载
nhder 255771 256015 https://nhentai.net/tag/lolicon/ https://nhentai.net/search/?q=fgo这时也可以使用上面提到的-p参数,并且会对所有分类或搜索页的输入起效
- 支持断点续下,精确到本子的页
- 由于程序运行时有下载临时文件清理机制,请勿多开
- 其实 nhentai 搜索有许多语法,请参考 https://nhentai.net/info/
最基础的是用空格隔开关键字,例如搜索东方的汉化本可以搜索touhou chinese,而不是仅搜索touhou然后依靠本程序的语言过滤,效率有天壤之别
| 支付宝 | 微信 |
|---|---|
 |
 |
感谢每一位捐赠者 XD