Background and History
XIVO is an open-source repository for visual-inertial odometry/mapping. It is a simplified version of Corvis [Jones et al.,Tsotsos et al.], designed for pedagogical purposes, and incorporates odometry (relative motion of the sensor platform), local mapping (pose relative to a reference frame of the oldest visible features), and global mapping (pose relative to a global frame, including loop-closure and global re-localization — this feature, present in Corvis, is not yet incorporated in XIVO).
Corvis is optimized for speed, running at 200FPS on a commodity laptop computer, whereas XIVO prioritizes readability and runs at 140FPS. XIVO incorporates most of the core features of Corvis, including 3D structure in the state, serving as short-term memory; it performs auto-calibration (pose of the camera relative to the IMU, and time-stamp shift). It requires the camera to have calibrated intrinsics, which can be obtained using any open-source package such as [OpenCV][opencv] prior to using Corvis or XIVO. Corvis and XIVO require time-stamps, which can be done through the ROS drivers. Please refer to the ROS message interfaces (imu,image) for details on how to format the data for real-time use.
We provide several recorded sequences, and the ability to run XIVO off-line in batch mode for comparison with other methods. Note that some of these methods operate in a non-causal fashion, by performing batch optimization relative to keyframes, or in a sliding window mode, introducing capture latency. XIVO is causal, and processes only the last image frame received. The latency of a vision update (time interval between the instant of capture and the time where a state update is performed) is about 7ms, depending on the hardware used. Updates based on inertial measurements depends on the integration scheme, and is about 1ms for the default selection.
Corvis has been developed since 2005 [Jones et al.], with contributors including Eagle Jones [ijrr11], Konstantine Tsotsos [icra15], and Xiaohan Fei [cvpr17,eccv18,icra19]. If you use this code, or any the datasets provided, please acknowledge it by citing [Fei et al.].
While the ‘map’ produced by SLAM, consisting of a sparse set of attributed point features, is only functional to localization, with the attributes sufficient for detection in an image, XIVO has been used as a building block for semantic mapping [Dong et al.,Fei et al.], where the scene is populated by objects, bounded by dense surfaces. Research code for semantic mapping using XIVO can be found here.
The first public demonstration of real-time visual odometry (Structure From Motion, or SFM) on commercial off-the-shelf hardware was given by Jin et al. [cvpr00] at CVPR 2000. Its use for visual augmentation (augmented reality) was demonstrated at ICCV 2001 [Favaro et al.], and ECCV 2002, where a virtual object was inserted in live video from a hand-held camera connected to a desktop PC. While SFM and SLAM are sometimes considered different, they are equivalent if structure is represented in the state and stored for later re-localization. This feature has been present in the work above since 2004 using feature group parametrizations, first introduced by Favaro et al. [iccv01]. Later public demonstrations of real-time visual odometry/SLAM include Davison [iccv03] and Nister et al. [cvpr04].
Corvis is based on the analysis of Jones-Vedaldi-Soatto [jones07] and was first demonstrated in 2008. The journal version of the paper describing the system was submitted in 2009 and published in 2011 [ijrr11]. It differed from contemporaneous approaches using the original MSCKF [Mourikis & Roumeliotis, 2007] in that it incorporated structure in the state of the filter, serving both as a reference for scale - not present in the original MSCKF - as well as a memory that enables mapping and re-localization, making it a hybrid odometry/mapping solution. One can of course also include in the model out-of-state feature constraints, in the manner introduced in the Essential Filter [Soatto 1994], or the MSCKF. The manner in which the Gauge transformation is handled is fundamentally different in Corvis and MSCKF: In the former, there is no uncertainty associated to Gauge transformations, since they just reflect an arbitrary choice of reference. In the latter, uncertainty grows over time.
XIVO builds on Corvis, has features in the state and can incorporate out-of-state constraints and loop-closure, represents features in co-visibile groups, as in Favaro et al. [iccv01], and includes auto-calibration as in Jones et al. [jones07]. XIVO was also part of the first visual-inertial-semantic mapping system first presented by Dong et al. [cvpr17] in 2016. Background material on SFM can be found in textbooks.
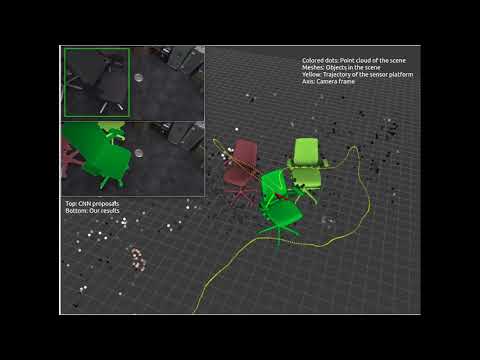
Fei et al. Visual-Inertial Object Detection and Mapping. ECCV 18.
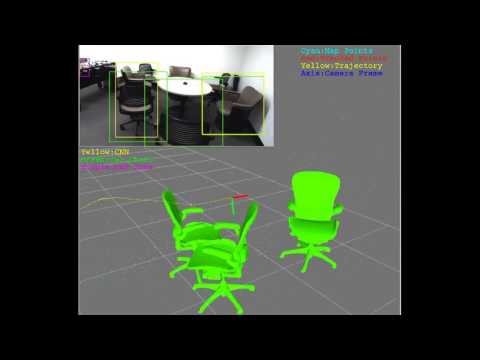
Dong et al.. Visual-Inertial-Semantic Scene Representation for 3D Object Detection. CVPR 17.
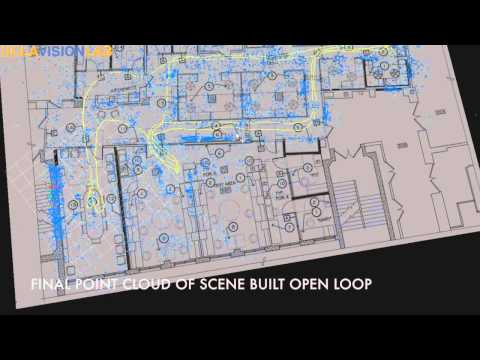
Tsotsos et al. Robust Inference for Visual-Inertial Sensor Fusion. ICRA 15.