Getting to know dcafs2
Document is being revised to fit 1.1.0, sections A-C done.
The purpose of this (probably in the end very long) page is to slowly introduce the different components in dcafs and how to use them. The basis will be interacting with a dummy sensor that simulates rolling a d20 (a 20 sided die). This sensor wil be simulated by another instance of dcafs running on the same system. Do note that practicality isn't the mean concern, showing what is (or isn't) possible is.
The dummy sensor is in fact just dcafs running a purpose made settings.xml and script.
Nothing in the source code has been altered to make it possible, so it should be independent of the version used (unless because of new bugs).
How the dummy works will be explained on this page (somewhere). The only thing that matters for now is that it is running a TCP server on port 4000.
Note: This guide assumes Java (at least 17, install the latest LTS version) and a telnet client (such as PuTTY) have been installed already. Dcafs doesn't have a GUI and uses a telnet server for interaction instead.
To start off with a glossary:
-
stream: tcp/udp/serial connection that can receive/transmit data -
source: any possible source of (processed) data -
command: a readable instruction that can affect any part of the program, always abbreviated to cmd -
forward: an object that receives data from a source, does something with it and then gives it to a writable
And some important commands:
- For a general beginners aid, use
help - To get an overview/status of all the streams,databases and such, use
st - To shut down the instance of dcafs,
sd:reasonfe.sd:updating to new version
- Download the latest release version of dcafs from the dcafs releases page. Pick the zip file that contains all files.
- Extract it to a working folder, make a second copy of it and rename that one to dummy. Keep the original.
- Download the Diceroller package
- Extract the content into the dummy folder (fe. settings.xml should be on the same level as the .jar)
- From now on, the dcafs version that generates the dummy (diceroller) data will be called "dummy", the other one we'll call "regular"
- Start both the regular and dummy dcafs (double-click on their respective .jar files). If your firewall (Windows Defender, ...) ask permissions you'll have to grant them.
Note: If you get a JNI error message, this likely means that it's not using the correct version of Java
- A
settings.xmlshould be generated in the regular folder. - Optional: Install an SQLite viewer like DB Browser for SQLite
Note: Dummy can be accessed via telnet if needed, it is listening on port 24 instead of the standard 23. Dcafs refuses to start if there is a telnet active on port 23. This prevents duplicate instances running.
The following is the recommended setup for setting up dcafs in general:
- Have two dcafs telnet instances open
- Open PuTTY, select telnet as the protocol, use
localhostas the ip, keep the default port.- Localhost means that dcafs is running on your PC/laptop 'locally'.
- Type 'dcafs' in the saved session and click 'Save'.
- Once open, right-click on the title bar and select 'Duplicate instance'. The opens a second instance.
- You'll probably want to make this window larger (or adjust it accordingly later)
- There's no real limit to the amount of instances.
- The idea is to use one window for showing long term info (like help etc. or data updates) and the other to issue other commands
- Open PuTTY, select telnet as the protocol, use
- Keep the settings.xml open and visible, notepad++ is a suitable lightweight editor
- It's possible to have it auto-update on changes done by dcafs
- Settings -> Preferences -> MISC. -> Update silently (checkbox) -> (click close)
- Working with xml is made a lot easier by installing the XML tools plugin
- Plugins -> Plugin Admin -> search for 'XML tools' (click next) -> click checkbox -> install
- This will auto-close nodes (something that's easily forgotten)
- It's possible to have it auto-update on changes done by dcafs
Connect to the 'regular' dcafs telnet.
As a first step type help, which would result in the screen below:
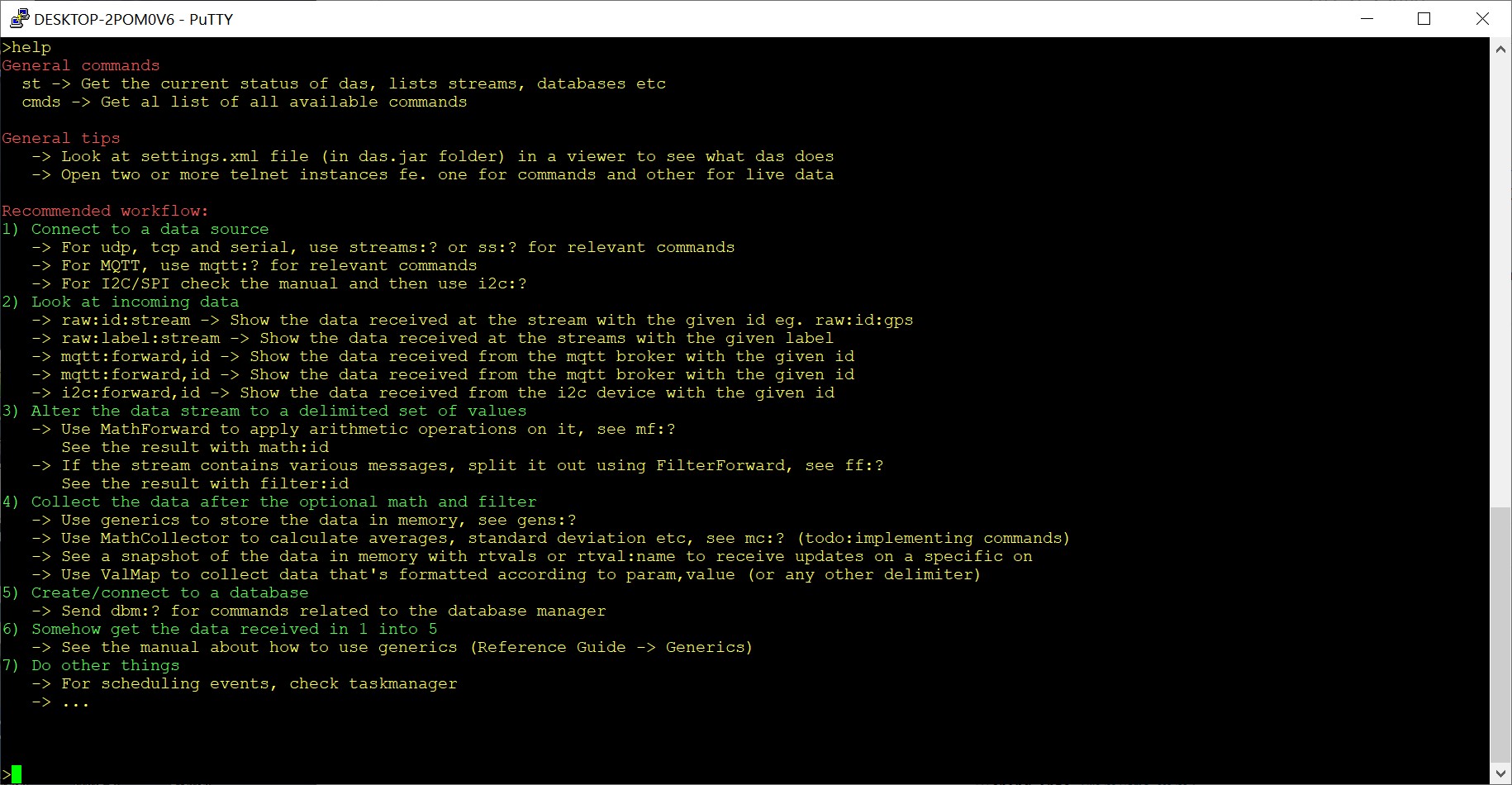
For the sake of consistency, we'll follow the 'recommend workflow' from the help.
Congratulations, you found a bug! Or made a typo...
If you suspect a bug, check the subfolder 'logs' it should contain a dated errorlog and a single info.log. Both might
give a hint on what went wrong.
If this doesn't help, create an issue about it (and maybe attach those logs)
and I'll look into it.
The datasource (our dummy simulating a d20 dice) is a TCP server. Typing ss:? in the (second) telnet session will give a lot
of information, but the only line interesting now is:
ss:addtcp,id,ip:port which connects to a tcp server.
For this example this becomes ss:addtcp,dice,localhost:4000.
You should see Connected to dice, use raw:dice to see incoming data. as the reply.
If you try that, hit enter to stop it.
Use st to see the current state of dcafs. This will give you a lot of info including a section about streams which
should look like this:
Streams
TCP [dice] localhost/127.0.0.1:4000 870ms [-1s]
To explain the whole line:
- TCP : It's a TCP connection
- [dice] : The ID is 'dice'
- localhost/127.0.0.1:4000 : The hostname is localhost, IP is 127.0.0.1, and we connected to port 4000
- 870ms : Received last data 870ms ago
- [-1s] : The stream is never considered idle, the term used for this period is ttl or 'Time to live'
If there's something wrong there are three options:
- NC at the beginning of the line means Not Connected
- !! at the beginning of the line means no data was received in the chosen timeout window (in our case this is [-1s], so disabled)
- No data yet at the end, means that no data has been received since the connection was made
Some properties of the stream can be changed via telnet commands. To do this, the command is like ss:alter,id,ref:value.
Some examples:
-
ss:alter,dice,ttl:3swould change the ttl for the connection to 3 seconds, do note that 3000ms is also allowed (as well as 1m10s, 1h etc.) -
ss:alter,dice,eol:crwould change the eol (end-of-line) character(s) to carriage return (\xD would also be accepted) from the default crlf (or \xD\xA)
Note: If you try them, this will change the settings you'll see below. Make sure to correct the settings file to match the one below before proceeding any further.
There are more, but those are the most commonly used.
What we did so far (starting up dcafs and connecting to a stream) generated a settings.xml file that looks like this (without some comments):
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<dcafs>
<settings>
<mode>normal</mode>
<!-- Settings related to the telnet server -->
<telnet port="23" title="dcafs"/> <!-- The telnet server is available on port 23 and the title presented is dcafs -->
</settings>
<streams>
<!-- Defining the various streams that need to be read -->
<stream id="dice" type="tcp">
<eol>crlf</eol> <!-- Messages should end with \r\n or carriage return + line feed -->
<address>localhost:4000</address> <!-- In the address, both ipv4 and hostname are accepted, IPv6 is wip -->
</stream>
</streams>
</dcafs>Some basic information about xml to start:
- Anything starting with and closing with , is called a node.
- The first such node is called the rootnode, so ...
- A node inside another node is called a childnode, so settings is a childnode of dcafs and so on
- A node can have content, so like eol has crlf as content
- A node without content and without childnodes can be closed with just a / like, so like telnet
- This is not mandatory, just makes it a bit shorter
- A node without content and without childnodes can be closed with just a / like, so like telnet
- A node can have attributes, the telnet node has port and title as attributes
Everything in a stream node of the settings.xml file (except the ID) can be altered while running and will be applied
without restart. To reload a stream after changing something in the streams node use ss:reload,id or in our case ss:reload,dice.
Or all at once with ss:reload.
Note: To connect to other datasources (like serial or modbus), the command
ss:?shows a list of options.
To see the data as it's coming in, use the raw:streamid command, so raw:dice.
Note: You don't need to type the full id, just make sure it at least 'starts with' and is the only option. So
raw:dicwould have worked or evenraw:d. Because no other stream id's start with dic or d.
Result could be (highly unlikely, because its random):
d20:9
d20:3
d20:7
d20:19
d20:12
To stop this constant stream of data, send an empty command (press enter).
Note: By default all data received (but not send) is stored in .log files that can be found in the /raw subfolder.
For now, the only thing done is storing the data from the dummy sensor in the raw data log file, that's it.
To actually keep the last value in memory there are multiple options. For now, we'll stick to the easiest one, 'store'.
Values in memory are referred to as 'rtvals', which stands for realtimevalues.
Some basic info about rtvals:
- There are currently four types: real,int,text and flag
- Each rtval belongs to a group and has a name, the id of the rtval is group_name
- A name can be repeated inside a group if the type is different, but it's better not to.
One way to create and set those values is called 'store', the name is from the optional node inside a stream.
Store splits incoming data and assigns the values to the predefined rtvals.
So, to define the store,we need to analyse the format of the data.
- Given that the data looks like 'd20:xx' in which:
-
d20is the prefix -
:is the delimiter -
xxis the possible roll result (1-20)
-
The data needs to be split on ':' and then the second element (but counting from 0) is the integer we want.
An overview of all the commands available for store is given with the store:? command.
Easiest is to open a second instance to display the result of that command.
Because all the commands start with the same store:streamid, we'll let the interface prepend this with store:dice,!!.
This tells dcafs that all the following things we'll send need to have everything in front of the '!!' appended.
Note: This can be cancelled by sending just !!
Now defining the store:
- First we'll set the delimiter to ':' with
delimiter,:- The default delimiter is ',', so if that was the case setting it can be skipped
- Next up is adding an integer
store:streamid,addint,id<,index>- which we'll call 'rolled' and it's at index 1 so this becomes
addint,rolled,1
- which we'll call 'rolled' and it's at index 1 so this becomes
Now that the store is defined, use !! to remove the prepending.
The result of those commands can be seen in the settings.xml.
<stream id="dice" type="tcp">
<eol>crlf</eol>
<address>localhost:4000</address>
<store delimiter=":">
<int index="1" unit="">rolled</int> <!-- unit isn't used for now -->
</store>
</stream>Everytime a store command is issued, dcafs applies those changes.
To see if it actually worked, look at the values in memory with rtvals.
Status at 2023-03-04 00:35:39
Group: dice
rolled : 20
- Because a group wasn't specified, the id of the stream is used.
- If we had filled in a
unitearlier, this would have been appended to the 20
Extra: you can get updates on specific rtvals using type:id so in this case int:dice_rolled or integer:dice_rolled.
Once again, press return to cancel the request for updates.
Another option isrtvals:name,rolled which list those with the name rolled (once instead of streaming).
Or if not so certain on the name rtvals:name,rol* or actually using regex rtvals:name,rol.*
(.* means any amount of any character)
The code doesn't differ much between SQLite or a database server, so we'll go with SQLite.
For a full list of database related commands, use dbm:?
The one we are interested in now is dbm:addsqlite,id(,filename), filename is optional, and the default is id.sqlite
inside the db subfolder.
So dbm:addsqlite,diceresults
Created SQLite at db\diceresults.sqlite and wrote to settings.xml
And indeed in the settings.xml the following section has been added (comments here added for information):
<databases>
<sqlite id="diceresults" path="db\diceresults.sqlite"> <!-- This will be an absolute path instead -->
<flush batchsize="30" age="30s"/>
<idleclose>-1</idleclose> <!-- Do note that this means the file remains locked till dcafs closes -->
<!-- batchsize means, store x queries before flushing to db -->
<!-- age means, if the oldest query is older than this, flush to db -->
<!-- idleclose means, if the connection hasn't been used for x period (eg. 10m), close it or never if -1 -->
</sqlite>
</databases>Next the database needs a table to store the results dbm:addtable,id,tablename(,format)
There are two options to do this, but we'll just show the shortest:
- Create the table with:
dbm:addtable,diceresults,dice - Add the first column with:
dbm:addcol,dice,utc:timestamp- addcol - short for add column
- dice - refers to the table, could also be diceresults:dice but given that there's only one dice this can be omitted
- utc:timestamp - utc is short for columntype 'utcnow' and the name is timestamp (utcnow is auto-filled)
- Add the second column with:
dbm:addcol,dice,i:rolled- All the same except it's i for integer (there's also t/text,r/real,ldt=localdt now,dt=datetime)
Note:
dbm:addcolumn,diceresults:dice,integer:rolledwould have the same result
This will have altered the sqlite node accordingly:
<sqlite id="diceresults" path="C:\local_home\GIT\dcafs\db\diceresults.sqlite">
<flush age="30s" batchsize="30"/>
<idleclose>-1</idleclose>
<table name="dice">
<utcnow>timestamp</utcnow>
<integer>rolled</integer>
</table>
</sqlite>To apply this dbm:reload,diceresults, this will generate the table in the database.
To check if it actually worked: dbm:tables,diceresults
Info about diceresults
Table 'dice'
> timestamp TEXT (rtval=dice_timestamp)
> rolled INTEGER (rtval=dice_rolled)
A column has a name and a rtval, the name is how it's called in the database while the rtval is the corresponding
rtval in dcafs. The default rtval is tablename_columnname.
Given that the earlier created rtval belongs to the group dice, this is the one that will be used.
Do note that the columntype of timestamp is TEXT. This is because sqlite doesn't have an equivalent and TEXT is the recommended columntype for datetime.
And st (for status) also got updated:
...
Databases
diceresults : db\diceresults.sqlite -> 0/30 (NC)
So now there's a database ready (go ahead and open the sqlite db in a viewer). It is, however, still empty as no data gets written to it... yet.
In order to actually get data in it, the store must know about where the data needs to go to.
With store:id,db,dbid:table which becomes store:dice,db,diceresults:dice.
The result:
<store db="diceresults:dice" delimiter=":" >
<int id="rolled" index="1" unit=""/>
</store>
<!-- db can contain multiple id's separated with "," but the table structure must match between databases.
As such, it's easy to have a sqlite database as backup for a server without any additional code -->Not sure if this is going to explain it or make it harder to understand.
The db attribute doesn't mean that the store is the one writing to the database.
If you check dbm:?, under the title 'Working with tables' there's dbm:store,dbid,tableid.
So what the store does is execute that cmd with the data from the attribute. In other words, there doesn't
have to be any link between the store and the table(s).
To check if something is actually happening, check st again, you'll see that it's no longer 0/30 (NC) and the
sqlite is slowly getting bigger.
This section will make small changes to the previous setup, mainly to show small variations and available options.
There are two ways to fix this, either change what the table looks for or what the store uses.
What the table looks for
A lot of attributes are hidden if they contain the default value. Suppose this wasn't the case and the tablename was actually 'd20s', then the node would have looked like this
<sqlite id="diceresults" path="db\diceresults.sqlite">
<flush age="30s" batchsize="30"/>
<idleclose>-1</idleclose>
<table name="d20s"> <!-- d20s instead of dice -->
<utcnow>timestamp</utcnow>
<integer rtval="d20s_rolled">rolled</integer> <!--rtval attribute is shown -->
</table>
</sqlite>So the easiest fix is to alter the rtval attribute in the xml to 'dice_rolled', save the file and then do
the dbm:reload,diceresults command again to apply it.
What the store uses
Just like the sqlite node, the store node also hides default attributes.
<store delimiter=":" group="dice">
<int index="1" unit="">rolled</int>
</store>The general rule is that if an attribute is defined in a node, the childnodes take the same value if it isn't defined.
So because int doesn't have a group node, it takes the value from the store node and becomes 'dice'.
Because all the rtval can belong to the other group, just using store:dice,group,d20s makes the changes.
<store delimiter=":" group="d20s">
<int index="1" unit="">rolled</int>
</store>Another option would have been:
<store delimiter=":">
<int group="d20s" index="1" unit="">rolled</int>
</store>It's called rollover (db rolls over to the next), the command for it dbm:addrollover,id,count,unit,pattern.
- id is the SQLite id
- count is the amount of unit to rollover on
- unit is the time period of the count, options are minute, hour, day, week, month, year
- pattern is the text that is added in front of .sqlite of the filename, and allows for datetime patters.
So as an example a monthly rollover: dbm:addrollover,diceresults,1,month,_yyyyMM.
To apply it: dbm:reload,diceresults (but note that you'll lose the queries in the buffer)
<databases>
<sqlite id="diceresults" path="db\diceresults.sqlite"> <!-- fe. db\diceresults_2021_05.sqlite -->
<rollover count="1" unit="month">yyyy_MM</rollover>
<flush age="30s" batchsize="30"/>
<idleclose>-1</idleclose>
<table name="dice">
<utcnow>timestmap</utcnow>
<integer>rolled</integer>
</table>
</sqlite>
</databases>Note: this just serves to show how to add a server to dcafs, this won't install said database server
Going back to the dbm:? command, its shown that database servers are also an option.
Let's take MariaDB as an example: dbm:addmariadb,id,db name,ip:port,user:pass
Suppose:
- give the id diceserver
- it's running on the same machine and using default port (then you don't need to specify it)
- It has a database with the same name as the sqlite one made earlier
- Security isn't great and user is admin and pass stays pass
The command becomesdbm:addmariadb,diceserver,diceresults,localhost,admin:pass
Which in turn fills in the xml.
Note: Attributes are sorted, that's why it's first pass and then user...
<databases>
<server id="diceserver" type="mariadb">
<db pass="pass" user="admin">diceresults</db>
<flush age="30s" batchsize="30"/>
<idleclose>-1</idleclose>
<address>localhost</address>
</server>
</databases>All the rest is the same as the SQLite. (meaning adding the table and using the generic with the new db attribute)
This should serve as a broad, toplevel overview of what happens and what goes where or has which function.
- Create a
stream. The ID will be what you use to refer to it afterwards.- Some references that can be altered:
ttl,eol.
- Some references that can be altered:
- A
storewill process the data by splitting it at the delimiter.- Each "field" that results from the split can be given a name and type (int, text ...)
- One of the attributes of a
storeis the group. This allows you to group incoming data (shown usingrtvals).
Restore the settings.xml to restart from a clean slate.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<dcafs>
<settings>
<mode>normal</mode>
<!-- Settings related to the telnet server -->
<telnet port="23" title="dcafs"/> <!-- The telnet server is available on port 23 and the title presented is dcafs -->
</settings>
<databases>
<sqlite id="diceresults" path="db\diceresults.sqlite"> <!-- fe. db\diceresults_2021_05.sqlite -->
<rollover count="1" unit="month">yyyy_MM</rollover>
<flush age="30s" batchsize="30"/>
<idleclose>-1</idleclose>
<table name="dice">
<utcnow>timestmap</utcnow>
<integer>rolled</integer>
</table>
</sqlite>
</databases>
<streams>
<!-- Defining the various streams that need to be read -->
<stream id="dice" type="tcp">
<address>localhost:4000</address>
</stream>
</streams>
</dcafs>Then use the sd command to shut down dcafs and start a new instance (launch the .jar).
As the name implies, a path defines how the data is processed in dcafs.
There are two options for the path nodes, either inside the settings.xml or in their own file. For small projects, inside the settings.xml is fine.
But when working with multiple (longer) paths it's recommended to give each path their own file. This also enables easier reuse.
For this example, the path will be added inside the settings.xml.
Paths have their own cmds, which are given with the pf:? cmd (pf=pathforward).
So create an empty path with: pf:addpath,cheat,raw:dice.
- cheat is the id of the path
- raw:dice is the source of the data
The result is an extra node added:
<paths>
<path delimiter="," id="cheat" src="raw:dice"/>
</paths>For now the path is empty, but 'steps' will be added (or childnodes in the xml). These are the 'steps' the data takes while being processed in the path.
A path doesn't need a delimiter, but the steps might. That's why a default delimiter can be set that will be used by a step if none is specified by it.
Because we'll use the same data as before, the delimiter can be altered to ':': pf:cheat,delim,:.
There's very little data to filter... unless you want to cheat! (in a much too obvious way)
Filtering is based on rules, the list of options at help:filter might contain something to cheat with.
Given how the data looks, choices are limited...
minlength : the minimum length the message should be
Let us use that to claim we never roll below 10, the command to add a filter with a single rule pf:pathid,addfilter/addf,rule:value.
Filled in: pf:cheat,addf,minlength:6
Now use path:cheat to see the result. If you don't see anything, it either doesn't work, or the rolls are really unlucky.
You could open a second telnet session and use raw:dice to see the unfiltered data.
Below is what was added to the settings.xml.
<paths>
<path delimiter=":" id="cheat" src="raw:dice">
<filter type="minlength">6</filter>
</path>
</paths>To write this to the database, a store node needs to be added. Because it's inside a path, the cmds are different.
All the cmds start with pf:pathid,store,, using !! again pf:cheat,store,!!
- Because a store takes group from the parent id (cheat), alter it
group,dice - To add (to) an int to a store:
addint,name<,index>, soaddint,rolled,1.- If a store is the last step in the path, the int will be added to that store
- If no store is at the end, a new one will be created for it.
- Then finally, to set the db reference,
db,diceresults:dice - Next
!!, to go back to normal entry
<store db="diceresults:dice" delimiter=":" group="dice">
<int index="1" unit="">rolled</int>
</store>Now when you check the rtvals or the database, results below 10 shouldn't appear anymore. But in the database, it might be obvious that there are gaps... this could be fixed but that's for another section.
Note: For now, a message much comply with all filters. The only exception to that rule is startswith, you can add multiple of those in a single filter, they will be or'd instead.
This is a really short intro into FilterForward, check the dedicated wiki page for more.
So we managed to cheat, but it's way too easy to spot, so we'll make it bit harder...
- Again to use !!,
pf:cheat2,!!- We'll add another path, so
new,raw:dice.
- We'll add another path, so
- Then we want a filter that removes values below 10
addf,maxlength:5 - Then add a math operation,
addm,i1=i1+5- Like earlier with the store, math also splits the data and those i's refer to that (and start at 0)
- The operation applied is i1=i1+5, so the number at index 1 will be increased with 5
- After this is done, the data is reconstructed fe. d20:5 -> d20:10
- Then just copy-paste the earlier made store underneath it or...
-
pf:cheat2,store,!!,group,dice,addi,rolled,1,db,diceresults:dice
-
- Back to normal input with
!!
Below is how it will look in xml.
<paths>
<path delimiter=":" id="cheat2" src="raw:dice">
<filter type="maxlength">5</filter>
<math>i1=i1+5</math>
<store db="diceresults:dice" delimiter=":" group="dice">
<int index="1" unit="">rolled</int>
</store>
</path>
</paths>So now if we use integer:dice_rolled we'll see rolled as it's updated. Add raw:dice to see the raw that is
used.
d20:16
dice_rolled:16
d20:1
dice_rolled:6
d20:11
dice_rolled:11
d20:7
dice_rolled:12
As a (last) reminder, press enter to stop the data from appearing.
Some extra info on maths:
- There's no limit to the amount of op's
- The op's are executed in order, so if the first one alters index 1 the next one will use the updated value
- Besides +, other supported ones are -,/,*,^ and %
- Brackets are allowed but not mandatory because it will follow the priority rules with the minor exception that % has lower priority than / and * (who share priority). So 5+2*4 will be 13 and not 28.
- Both Scientific notation (15E2) and hexadecimal (0xFF) are allowed in both data received and op's.
There's no function (yet) for logical operations in MathForward nor FilterForward, so that's it for cheating... It still might be obvious that 1 to 5 never appear but there's little that can be done about that (for now), besides its random, so we might just be lucky.
This was a really short intro into MathForward, check the dedicated wiki page for more.
The third forward is capable of altering the data with string operations.
There are to many edit options to list here, so use help:editor to get an overview including example xml syntax.
The most commonly used ones:
- replace - replace one string with another one
- remove - remove a certain string from the data
- resplit - reorder the data and alter as needed
Usage is pretty much the same as filters, this editor will pretend that we actually wanted a d10 instead of a d20 if the result was less than 10.
Start of with altering cheat2 to this.
<path delimiter=":" id="cheat2" src="raw:dice">
<filter type="maxlength">5</filter>
</path>To add an editor that does a replace, check the earlier help:editor for the correct sequence.
replace -> Replace 'find' with the replacement cmd pf:pathid,adde,replace:find|replacement
So this becomes: pf:cheat2,adde,replace,d2|d1
<path delimiter=":" id="cheat2" src="raw:dice">
<filter type="maxlength">5</filter>
</path>Or if you want to reduce it to a single line:
<path delimiter=":" id="cheat2" src="raw:dice">
<filter type="maxlength">5</filter>
<editor>
<!-- Replace d2 with d1 -->
<edit type="replace" find="d2">d1</edit>
</editor>
</path>Now remove the last node with pf:cheat2,delete,last.
The resplit one is a bit more complex so to give an example of yet another cheat method.
According to help:editor, the cmd is pf:pathid,adde,resplit,delimiter|append/remove|format.
- The delimiter is the same as before, so
:. - The append/remove refers to what is done with the items that aren't mentioned in the format. If it's split in four but the format only refers to two, append will have those appended at the end (using delimiter) and remove will discard.
- Format will be
i0:1i1so just add a 1 in front of the second item. Because the filter only allows rolls below 10 to go through, this results in those rolls becoming much better.
Based on that the cmd becomes: pf:cheat2,adde,resplit,:|append|i0:1i1
<path delimiter=":" id="cheat2" src="raw:dice">
<filter type="maxlength">5</filter>
<editor>
<!-- Split on : then combine according to i0:1i1 -->
<edit delimiter=":" leftover="append" type="resplit">i0:1i1</edit>
</editor>
</path>Check the result with path:cheat2.
So far we made a path for each filter, but it's actually the same when combining.
<path delimiter=":" id="cheat" src="raw:dice">
<filter type="minlength">6</filter>
<store db="diceresults:dice" delimiter=":" group="dice">
<int index="1" unit="">rolled</int>
</store>
<!-- because the previous step was a 'store', dcafs assumes you're done with the filtered data -->
<!-- So the next step will get the discarded data -->
<filter type="maxlength">5</filter>
<math>i1=i1+5</math>
<store db="diceresults:dice" delimiter=":" group="dice">
<int index="1" unit="">rolled</int>
</store>
</path>Note that the output of the path:cheat will be the result of the second filter because that's what reaches the end of
the path.
If this is unwanted behaviour, it's possible to override it.
<paths>
<path delimiter=":" id="cheat" src="raw:dice">
<filter id="f1" type="minlength">6</filter> <!-- the filter was given an id -->
<store db="diceresults:dice" delimiter=":" group="dice">
<int index="1" unit="">rolled</int>
</store>
<!-- because the previous step was a 'store', dcafs assumes you're done with the filtered data -->
<!-- So the next step will get the discarded data -->
<math src="filter:f1">i1=i1+5</math> <!-- refer to filter with id f1 as the source -->
</path>
</paths>-
streamtcp/udp/serial connection that can receive/transmit data -
sourceany possible source of (processed) data -
commanda readable instruction that can affect any part of the program -
patha series of steps that the data passes through to get processed
A major aspect of dcafs is the concept of source and writable. Source means 'it can provide data' while writable means
'it can accept data'. Most components are both, when the raw data was provided to the filter, the stream was the source,
and the filter the writable (which in turn became a source).
Everytime you want to see data in telnet, that interface acts as the writable.
Not that it matters for the user, but for example a filter will only request data from its source if it has a writable/target for the
filtered data.
- For a general beginners aid, use
help - To get an overview of all the streams,databases and such, use
st - If you want to collect data from TCP,UDP and serial,
ss:?- Once you have this data, get it with
raw:id
- Once you have this data, get it with
- If you have the data, but it needs filtering,
help:filter - If (even after filtering) the data still needs some maths,
help:math - If (even after filtering) the data still needs some edits,
help:editor - If you are happy with the data, store it in memory,
store:?- The resulting data can be seen with
rtvals
- The resulting data can be seen with
- For persistent storage in a database,
dbm:?- The easiest way to keep track of this is by checking
stand seeing the */30 go up
- The easiest way to keep track of this is by checking
- To shut down the instance of dcafs,
sd:reasonfe.sd:updating to new versionor justsd
For consistency's sake, a lot of subcommands are repeated.
-
cmd:?gives info on the command -
cmd:listgives a list of all the elements with some info (fe.ff:listwill list all the filters) -
cmd:addwill be the start of creation of a new/blank element -
cmd:reloadwill reload all the elements of the component -
cmd:reload,idwill reload the element with that id
Bonus!
- The up/down arrow can be used to go through history of send commands.
Now that we got the basics looked at, we'll expand on it.
This previously was just connecting to a TCP server and getting the data from it. The actual absolute minimum:
<stream id="dice" type="tcp">
<address>localhost:4000</address>
</stream>So a lot can be omitted and then dcafs will just assume the default values (which are hard coded).
It's up to the user to add these or not (if using the defaults).
<streams>
<stream id="dice" type="tcp">
<log>yes</log> <!-- by default, data is written to the raw logs, note that true/yes/1 are the same-->
<ttl>-1</ttl> <!-- by default, no ttl/idle is active -->
<eol>crlf</eol> <!-- default end of line sequence is carriage return + linefeed -->
<echo>false</echo> <!-- by default, data isn't looped back to the sender, note that false/no/0 are the same -->
</stream>
<!-- For a serial stream -->
<stream id="dice" type="serial">
<!-- All of the above and... -->
<serialsettings>19200,8,1,,none</serialsettings> <!-- by default, baudrate is 19200 with 8 databits,one stopbit and no parity -->
</stream>
</streams>This also means that the evidence of the earlier cheating is present in the log files...
So far we were only on the receiving end from a stream, no talking back yet.
Sending data isn't anything special and certainly not 'kicking it up a notch', but the bit afterwards will be...
Send streams (or ss) to get a list of available streams, this will return a list with currently only S1:dice
-
S1:importantto send important to the dice stream -
ss:send,dice,unimportantto send unimportant to the dice stream
As always, this has a couple of extras...
- by default, the earlier defined eol is appended (so the first command actually sends important\r\n)
- hexadecimal escape characters are allowed, so
S1:hello?andS1:hello\x3Fsend the same thing- alternatively,
S1:\h(0x68,0x65,0x6c,0x6c,0x6f,0x3f,0xd,0xa)would do the same thing, note that the eol sequence needs to be added manually
- alternatively,
- ending with \0 will signal to dcafs to omit the eol sequence so
S1:hello?\0won't get crlf appended.- Since 1.0.9, it's also possible to use CTRL+s to omit sending eol sequence
- If you plan on transmitting multiple lines, you should start with
S1:!!from then on, everything send via that telnet session will have S1: prepended and thus be transmitted to dice. Sending!!ends this.
This feature can also be used to repeat a certain command over and over, because then it will just send the prepended part.
So now you know pretty much everything there is to know about manually sending data.
Let's put it to some use.
Have two telnet sessions open:
-
raw:dicerunning in one to see the rolls come in - send
S1:dicer:stopd20sin the other one, this should stop the d20 rolls to arrive in the first one
The dicer accepts more commands, to test them out first send S1:dicer:!! so that is prepended.
-
rolld6rolls a single 6 sided die -
rolld20rolls a single 20 sided die -
rolld100rolls a 100 sided die -
stopd20sstops the continuous d20 stream -
rolld20sstarts the continuous d20 stream
(send !! to go back to normal)
Next up will introduce triggered actions, which are also the final nodes for the stream.
<stream>
<cmd when="">cmd</cmd>
<!-- or -->
<write when="">data</write>
</stream>A stream can have multiple of these cmd/write nodes and there are a couple 'when' options.
- To write data:
-
helloto send something upon (re)connecting -
wakeupto send something when the connection is idle
-
Suppose we don't actually want to receive the d20s, but want a d6 every 5 seconds...
The command to add a 'write' is ss:addwrite,id,when:data so:
-
ss:addwrite,dice,hello:dicer:stopd20sto send the stop -
ss:addwrite,dice,wakeup:dicer:rolld6to request a d6 on idle -
ss:alter,dice,ttl:5sto trigger idle after 5s of not receiving data
<stream id="dice" type="tcp">
<address>localhost:4000</address>
<write when="hello">dicer:stopd20s</write> <!-- send the text to stop getting the d20s upon connecting -->
<ttl>5s</ttl> <!-- because of no longer receiving data this will expire -->
<write when="wakeup">dicer:rolld6</write> <!-- and a d6 will be asked because of the ttl -->
<!-- After receiving the d6 result, after 5s another ttl trigger etc... -->
</stream>Then ss:reload,dice and d6 results should appear every 5 seconds.
Just to clarify, this is not the proper way to handle this situation and just serves to show the functionality.
This should actually be done using the TaskManager, but that's for a later section. Do note that dicer is actually
a taskmanager running on dummy...
The cmd node has four 'when' options, but those are for issuing (local) commands instead of writing data.
-
openexecuted on a (re)connection -
idleexecuted when the ttl is passed and thus idle -
!idleexecuted when idle is resolved -
closeexecuted when it's closed
These can be added with the command ss:addcmd,id,when:data
So the main difference is that hello and wakeup send data to somewhere, while open,idle and close are local commands.
For the next example, we'll shut down both instances. Shutting down the dummy can be done by sending S1:sd to it.
Then use sd to close the regular one.
Note: The full command is sd:reason, this allows the user to give a reason for the shutdown that will be logged.
We'll automate this.
- First restart the dummy, don't start the regular one yet
- Open a telnet connection to the dummy on port 24
- Send
raw:dummy(in the dummy session) to later notice the updates stopping - Alter the stream node in the xml for the regular one
<stream id="dice" type="tcp">
<address>localhost:4000</address>
<write when="hello">dicer:stopd20s</write> <!-- send the text to stop getting the d20s upon connecting -->
<ttl>6s</ttl> <!-- because of no longer receiving data this will expire -->
<write when="wakeup">sd</write> <!-- and a shutdown will be asked because of the ttl -->
<cmd when="close">sd</cmd> <!-- which in turn will trigger a 'close' that will shutdown this instance -->
</stream>- Start the regular one and open a telnet connection on port 23
- Shortly after no more updates will appear in the dummy session
- After about 6 seconds it will close and shortly after the regular one
Again this is purely to show the functionality, every command that can be issued through telnet can be used this way.
For example,the two nodes below have exactly the same end result:
<stream>
<cmd when="open">ss:send,dicer,hello!</cmd> <!-- execute ss:send,dicer,hello! on connectino established -->
<write when="hello">hello!</write> <!-- send hello! on connection established-->
</stream>Problem is that giving actual useful examples is hard because it involves components not seen yet...
- command a taskmanager to do something on opening or closing a connection (and something is an understatement)
- email someone on connection loss or gain
- send data to one device if another one is idle
- ...
But, I assume that it's clear what it can be used for...?
What was shown so far was when dcafs needs to figure out the relationship between a table and a store.
Which has the advantage of being easy to explain, but it's not the most performant option.
Next a couple of alternative scenario's will be shown.
We are also interested in the results of rolling a d6 (6 sided dice) and want to store that in another table.
So first close dcafs and dummy, delete the diceresults.sqlite file and overwrite the xml to match the one below.
Anything new/added will be explained in the comments.
<dcafs>
<settings>
<mode>normal</mode>
<!-- Settings related to the telnet server -->
<telnet port="23" title="dcafs"/>
<databases>
<sqlite id="diceresults" path="db\diceresults.sqlite">
<setup batchsize="10" flushtime="10s" idletime="-1"/>
<table name="d20s">
<utcnow>timestamp</utcnow>
<integer>rolld20</integer> <!-- column added to store the d20 -->
</table>
<table name="d6s"> <!-- Add an extra table for d6s -->
<utcnow>timestamp</utcnow>
<integer>rolld6</integer>
</table>
</sqlite>
</databases>
</settings>
<stream id="dice" type="tcp">
<address>localhost:4000</address>
<write when="hello">dicer:rolld6s</write> <!-- We also want to receive d6 results -->
</stream>
<paths>
<path id="sort" src="raw:dice" delimiter=":">
<filter type="start">d20</filter> <!-- redirect the d20's -->
<store db="diceresults:d20s" group="d20s">
<integer index="1">rolld20</integer>
</store>
<!-- From this point, the data discarded by the previous filter is given -->
<filter type="start">d6</filter> <!-- redirect the d6's -->
<store db="diceresults:d6s" group="d6s">
<integer index="1">rolld6</integer>
</store>
</path>
</paths>
</dcafs> Start both dummy and then dcafs again.
What will happen:
- The dummy will be asked to also send d6 results over the same connection
- The path will process the data so both stores are used when needed.
- If a d20 is received it will pass the first filter and thus be stored by the first store
- If a d6 is received it will be discarded by the first filter but passed on to the second one etc.
So the above shouldn't be anything new, next changes will be made.
At the moment each store triggers an insert into its own table, but now those need to be combined.
Simplest option would be to provide the earlier mentioned rtval attribute:
<table name="rolls">
<utcnow>timestamp</utcnow>
<integer rtval="d20s_rolld20">rolld20</integer>
<integer rtval="d6s_rolld6">rolld6</integer> <!-- column added to store the d6 -->
</table>This tells dcafs to look for d20s_rolld20 instead of rolls_rolld20 etc.
But suppose the table actually looked like this.
<table name="rolls">
<utcnow>timestamp</utcnow>
<integer>rolld20</integer>
<integer>rolld6</integer> <!-- column added to store the d6 -->
</table>Then the groups of the stores need to be altered.
<path id="sort" src="raw:dice" delimiter=":">
<filter type="start">d20</filter> <!-- redirect the d20's -->
<store db="diceresults:rolls" group="rolls">
<integer index="1">rolld20</integer>
</store>
<!-- From this point, the data discarded by the previous filter is given -->
<filter type="start">d6</filter> <!-- redirect the d6's -->
<store group="rolls">
<integer index="1">rolld6</integer>
</store>
</path>If the d6 store should be the trigger, just move the db attribute to it. If both stores have the db attribute, both will
trigger a database insert.
This means that the rolls written to the database will be the ones that are currently in the rtvals collection and the
timestamp will refer to the roll that initiated the trigger!
So if triggered by the d20 roll, the timestamp in the database is the timestamp of the d20 roll, the d6
entry will just be whatever is in rtvals at that time.
Note: If multiple stores should be used for the same table with data from the same sensor it's not guaranteed that the order the data arrives is the order that the stores are triggered if the processing of one message takes longer than the other one because processing happens multithreaded.
That is done with the def attribute in the column node.
If the corresponding rtval isn't found def will be used instead (if no def is defined, this will be null).
<table name="rolls">
<timestamp>timestamp</timestamp>
<integer>rolld20</integer>
<integer def="6">rolld6</integer> <!-- column added to store the d6 -->
</table>This pretty much covers it (for now).
All the above was based on using a src to get data into a path, but a path could also create the data.
The most basic example would be:
<paths>
<path id="custom">
<customsrc>Hello World?</customsrc>
</path>
</paths>Calling path:custom will print 'Hello World?' every second (1s is the default interval).
On the other hand, with a different interval:
<paths>
<path id="advexample">
<customsrc interval="3s">Hello World?</customsrc>
</path>
</paths>Another alternative is to use a cmd as the src...
<paths>
<path id="stupdate">
<customsrc interval="10s">st</customsrc>
</path>
</paths>When using path:stupdate in a telnet session, the result of st will be shown every 10s.
Up till now the only rtval used are the integers. But there's also real, text and flag(boolean).
So far to get data stored in memory, the only option was to go through store.
It's possible to create a 'global' store of rtvals using the same commands as earlier.
Same as before, the listing is shown with store:?. The only difference now is that 'global' is used instead of
the streamid to refer to the 'global' store.
In addition, each rtval has a single command to update the value:
- realval:
rv:id,update,expression, expression means operations and values are allowed (and references to other reals) - intval:
iv:id,update,expression, same as real - flagval:
fv:id,update,state, state is anything that can be parsed to a valid bool (0/1,yes/no,true/false) - textval:
tv:id,update,value, value is pretty much anything
These can be used in telnet etc.
We saw how to write to the rtvals but not how to read them:
- real: {r:id} or {real:id}
- int: {i:id} or {int:id}
- text: {t:id} or {text:id}
- flag: {f:id} or {flag:id}
This is possible in various places:
- cmd: Allows both r and f
rv:offsettemp,update,{r:temp}+5*{f:withoffset}do note that offsettemp must already exist. - forwards:
<examples>
<math>{r:offsettemp},i0={r:temp}+5*{f:withoffset}</math>
<!-- Only one ref can be given on the left, if not needed the i0 can be omitted on the left -->
<!-- Editor can also use them in the resplit command -->
<editor type="resplit">i0,i1,{r:temp}</editor>
<!-- These WILL FAIL if a real doesn't exist -->
</examples>Note: Although the above math can be used to update the val, it's probably better to use a store for that.
Rtvals also have their own xml structure to prepare them in advance and add some metadata.
<rtvals>
<group id="temps"> <!-- Multiple rtvals can belong to a single group -->
<real>temp</real> <!-- Without metadata -->
<real unit="°C" default="-999">offsettemp</real> <!-- With the unit and start value as metadata-->
</group>
<group id="info">
<text default="outdoor">location</text>
<flag default="no">serviced</flag>
</group>
</rtvals>Other metadata
- reals: fractiondigits or scale attribute: will round the value to that amount of digits
- reals/integers have a history node : keep x values of history in memory, no use through xml yet
<rtvals>
<group id="">
<real options="scale:1,history:10" >humidity</real>
</group>
</rtvals>As usual these (except text) allow for triggered commands. So combining the earlier seen things... Just like with math, '$' will be replaced with the updated value.
<rtvals>
<group id="temps">
<real unit="°C" default="-999">offsettemp</real>
<real name="temp"> <!-- Because there are childnodes, the name of the real is now an attribute -->
<cmd>rv:temps_offsettemp,update,$+5</cmd> <!-- When temp is updated, offsettemp will be calculated -->
<!-- $ is replaced with the new value of temp -->
<cmd>rv:temps_offsettemp,update,$+{r:offset}</cmd> <!-- Is also allowed if offset exists -->
</real>
<int name="otherval" unit="°C"/> <!-- It's also allowed to use name attribute when there are no childnodes -->
</group>
</rtvals>So a command can be issued everytime a value is set, that is the default trigger...
All options:
<real>
<cmd when="always">rv:temps_offsettemp,update,$+5</cmd> <!-- default is always execute -->
<cmd when="changed">rv:temps_offsettemp,update,$+5</cmd> <!-- only run if the new value is different from the previous one -->
<cmd when="below x">rv:temps_offsettemp,update,$+5</cmd> <!-- runs once if the value drops below x, reset when going above -->
</real>Besides 'below', the other options are:
- not below
- (not) above
- x through y
- (not) between x and y
- (not) equals x
Notes:
(1) It's really easy to create an endless loop with this, the user is responsible for not causing it!
(2) I'd rather have used logical symbols like <,>,>= etc but some of them aren't allowed in xml
<rtvals>
<group id="temps">
<real name="temp">
<cmd>rv:update,temp,$+5</cmd> <!-- Endlessly increase temp with 5 -->
</real>
</group>
</rtvals>-
rtvals:group,groupidwill return a list of all rtvals belonging to requested group, fe. the earlier temps
Group: temps
temp : -999°C
offsettemp : -999°C
location : outdoor
serviced: false
In contrast to the earlier basics, these components might see frequent use but might just as well be not used at all.
It's possible to send emails using smtp or connect to an imap server.
When sending email:? you'll get the following response:
No EmailWorker defined (yet), use email:addblank to add blank to xml.
So email:addblank will add the following section to the settings.xml (without the additional comments).
These need to be altered to match the server used.
Note: You don't need to define both. If no email need to be received, just delete that node.
<email>
<!-- Settings related to sending -->
<outbox>
<server pass="" port="993" ssl="yes" user="">host/ip</server>
<from>das@email.com</from> <!-- The email address that will show up in the 'from' field -->
<zip_from_size_mb>3</zip_from_size_mb> <!-- Attachments larger than this size will be zipped -->
<delete_rec_zip>yes</delete_rec_zip> <!-- If a received zip should be deleted after unpacking -->
<max_size_mb>10</max_size_mb> <!-- Zipped files larger than this amount WONT be send -->
</outbox>
<!-- Settings for receiving emails -->
<inbox>
<server pass="" port="465" ssl="yes" user="">host/ip</server>
<checkinterval>5m</checkinterval> <!-- How often should the worker check for new emails -->
<!-- If an email was received, the interval will temporary decrease to about a third of what was set -->
<!-- this is done to quicker reply to follow ups -->
</inbox>
<!-- Add entries to the emailbook below -->
<book> <!-- This is a list of known contact for the instance, only emails mentioned here can issue commands -->
<entry ref="admin">admin@email.com,anotheradmin@email.com</entry>
<entry ref="scientist">user@email.com</entry>
</book>
</email>Once altered, use email:reload to make it active and then the command email:? becomes available.
The only command we are interested in for now is email:send,to,subject,content.
A simple use case might be wanted to be informed if a certain device goes idle:
<stream id="dice" type="tcp">
<address>localhost:4000</address>
<ttl>6s</ttl> <!-- because of no longer receiving data this will expire -->
<!-- send an email to admin to inform about ttl being passed -->
<cmd when="idle">email:send,admin,Dice idle,No data received for 6s</cmd>
</stream>Note: A shorter version of the command is
email:toadmin,Dice idle,No data received for 6sthis only works for admin.
It can be used in a couple more cases, but those will be covered as examples in further chapters.
For more info, it's also possible to read the reference guide.
One of the main components of dcafs is the taskmanager functionality.
Reset the settings.xml back to this and restart dcafs:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<dcafs>
<settings>
<mode>normal</mode>
<!-- Settings related to the telnet server -->
<telnet port="23" title="dcafs"/> <!-- The telnet server is available on port 23 and the title presented is DAS-->
</settings>
<streams>
<!-- Defining the various streams that need to be read -->
<stream id="dice" type="tcp">
<eol>crlf</eol> <!-- Messages should end with \r\n or carriage return + line feed -->
<address>localhost:4000</address> <!-- In the address, both ipv4 and hostname are accepted IPv6 is wip -->
</stream>
</streams>
</dcafs>Back in the telnet interface, send tm:addblank,dicetm to create an empty taskmanager called dicetm.
Tasks script created, use tm:reload,dicetm to run it.
In the settings.xml the following line has been added.
<taskmanager id="dicetm">tmscripts\dicetm.xml</taskmanager>If you check the tmscripts' folder, a file dicetm.xml should be present with the following content which serves as both a 'blank' starting script and basic explanation.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<tasklist>
<!-- Any id is case insensitive -->
<!-- Reload the script using tm:reload,dicetm -->
<!-- If something is considered default, it can be omitted -->
<!-- There's no hard limit to the amount of tasks or tasksets -->
<!-- Task debug info has a separate log file, check logs/taskmanager.log -->
<!-- Tasksets are sets of tasks -->
<tasksets>
<!-- Below is an example taskset -->
<taskset id="example" info="Example taskset that says hey and bye" run="oneshot">
<task output="telnet:info">Hello World from dicetm</task>
<task output="telnet:error" trigger="delay:2s">Goodbye :(</task>
</taskset>
<!-- run can be either oneshot (start all at once) or step (one by one), default is oneshot -->
<!-- id is how the taskset is referenced and info is a some info on what the taskset does, this will be
shown when using dicetm:list -->
</tasksets>
<!-- Tasks are single commands to execute -->
<tasks>
<!-- Below is an example task, this will be called on startup or if the script is reloaded -->
<task output="system" trigger="delay:1s">taskset:example</task>
<!-- This task will wait a second and then start the example taskset -->
<!-- A task doesn't need an id but it's allowed to have one -->
<!-- Possible outputs: stream:id , system (default), log:info, email:ref, manager, telnet:info/warn/error -->
<!-- Possible triggers: delay, interval, while, ... -->
<!-- For more extensive info and examples, check Reference Guide - Taskmanager in the manual -->
</tasks>
</tasklist>To activate it use tm:reload,dicetm, 'Hello world from dicetm' should show in green and 'Goodbye :(' follows a
couple seconds later in red. (fyi telnet:warn is in something that should resemble orange)
A while back this was given as an option to get a d6 roll every 5 seconds.
<stream id="dice" type="tcp">
<address>localhost:4000</address>
<ttl>5s</ttl> <!-- because of no longer receiving data this will expire -->
<write when="wakeup">dicer:rolld6</write> <!-- and a d6 will be asked because of the ttl -->
<!-- After receiving the d6 result, after 5s another ttl trigger etc... -->
</stream>It was also stated that this wasn't the best way to solve it. What should have been done is use the taskmanager for it, like below:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<tasklist>
<tasks>
<!-- This introduces a third output option called 'stream' which takes an id as secondary argument -->
<!-- As the name implies, the value of the task (dicer:rolld6) will be send to the stream with id dice -->
<task output="stream:dice" trigger="interval:5s">dicer:rolld6</task>
<!-- By default the initial delay is taken the same as the interval, so the first run is 5 seconds after start -->
<!-- Alternative is trigger="interval:1s,5s" etc to change the initial delay, main use would be spreading multiple -->
<!-- interval tasks with the same interval -->
</tasks>
</tasklist>So enable this with tm:reload,dicetm.
Next, open a second telnet session and send raw:dice. You should see a d6:x appear once every 5 or so d20:x. We'll use
this session to monitor the output and the first one to issue cmds.
If you ever forget the name of the taskmanager(s), use tm:list to get a list.
As usual tm:? gives a list of all the available taskmanager commands. Furthermore, any task/tasket with an id, can be
called from telnet using tmid:taskid/tasksetid.
To test this add the following task:
<!-- This task has no trigger (just like a taskset) so it will only run when called -->
<task id="getd100" output="stream:dice" >dicer:rolld100</task>Again, reload with tm:reload,dicetm (the other session output will stop briefly).
Now send dicetm:getd100 to test if the addition causes a d100:x to appear in the other session or send dicetm:list to get
an overview of all the tasks/tasksets in the taskmanager.
If, for example, you want to request a d6,d20 and d100 with one command you'd make a taskset like this.
<taskset id="rollall" run="oneshot" info="Roll a d6, then a d20 and finally a d100">
<task output="stream:dice" trigger="delay:0s">dicer:rolld6</task>
<task output="stream:dice" trigger="delay:250ms">dicer:rolld20</task>
<task output="stream:dice" trigger="delay:500ms">dicer:rolld100</task>
</taskset>This uses the trigger 'delay' which just means 'wait the given time before execution'. A delay of 0s is the default in tasksets, but for readability it's advised to add it anyway.
This above taskset could be called with dicetm:rollall.
Or you could combine the two and have the above on an interval of 5s.
<task output="manager" trigger="interval:5s">task:rollall</task>
<!-- Output manager is used to signify that the value is a command for the active taskmanager -->And a last basic example:
<task output="email:admin" trigger="delay:5s">DCAFS booted;Nothing else to say...</task>
<!-- This will send an email to admin 5s after startup, subject of the email is DCAFS booted and the content 'Nothing...' -->
<!-- It's also possible to use a command as content, the result of that command (fe.st) will become the email content -->Going back to:
<stream id="dice" type="tcp">
<address>localhost:4000</address>
<write when="wakeup">dicer:rolld6</write>
</stream>Dummy has a taskmanager called 'dicer' and 'rolld6' is a task from it..
<task id="rolld6" output="stream:dummy" >d6:{rand6}</task>This is the minimum knowledge you need to use the taskmanager, but this is just brushing the surface... In later chapters examples will introduce the rest of the functionality. But to get a full overview of all the capabilities now, check the reference guide.
This introduced:
- In general, a taskmanager has tasks and tasksets
- tasksets
- are always executed on a command
- are either one-shot (all tasks are triggered at the same time) or step (one-by-one)
- an id is required
- tasks
- without a trigger are executed with a command, otherwise as response to the trigger
- an id is optional
- tasksets
- trigger options:
- interval Task is executed at a set interval after an initial delay
- delay Task is executed after the delay has passed
- output options:
- stream The value of the task is sent to a stream/raw
- system The value of the task is a command or reference to another task(set)
- email The value of the task is subject;content of the email
Other parts of it will be introduced later.
Earlier in the database & generics chapter the way of triggering a database write was using a generic.
If more updates are given than you'd want to store in the database, it's also possible to limit this with the taskmanager.
The earlier shown cmd dbm:store,dbId,tableid can be called with the system output.
<task output="system" trigger="interval:10s">dbm:store,diceresults,rolls</task>So if the rolls come in every second, this will cause a single result to be stored every 10 seconds instead.
Given you didn't forget to remove the db attribute from the generic...
This is a single TCP server that can be actived with the command ts:create.
Doing so, will add the following section to the settings.xml.
<transserver port="5542"/> <!-- This number was randomly chosen at some point -->Now the server is active and can be connected to. (putty raw localhost:5542)
Welcome back 0:0:0:0:0:0:0:1!
By default, everything send to this server will be assumed to be a command. However, compared to telnet, replies won't be
received. Because of this, it's made possible to change the label of this interface >>>label:telnet will make it behave like
a telnet session. The label can be verified using >>>label?.
The 'welcome back' above indicates that sessions can be stored.
-
Give the session an id,
>>>id:transtest
Check this with either>>>id?or (if using in telnet or system label )ts:listServer running on port 5542
0 -> transtest -->So the session with index 0 and id transtest is without requests.
-
Request data, there are two options to do this. But these are only valid as long as the connection is active.
- When using system or telnet label, it's the same as a telnet instance so
raw:diceshould show dice results - From any telnet instance,
ts:add,0,raw:diceorts:add,transtest,raw:dicehas the same effect
- When using system or telnet label, it's the same as a telnet instance so
-
To store this
ts:store,0orts:store,transtest
<transserver port="5542">
<default address="127.0.0.1" id="transtest">
<cmd>raw:dice</cmd>
</default>
</transserver>- Alternatively, start with
>>>recordthis will tell the server to record all command issued. Then sendraw:diceand any other commands, followed with>>>store. The result is the same xml node. - Now if the session is closed and reopened, dice results should start coming in.
Looks familiar? Below is the settings.xml from the dummy dice roller.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<dcafs>
<settings>
<mode>normal</mode>
<!-- Settings related to the telnet server -->
<telnet port="24" title="Dummy Sensor">
<ignore/>
</telnet>
<transserver port="4000">
<default address="127.0.0.1" id="local">
<cmd>raw:dummy</cmd> <!-- Request data received on dummy stream -->
</default>
</transserver>
<taskmanager id="dicer">scripts\dum.xml</taskmanager>
</settings>
<streams>
<!-- A local stream for the taskmanager to write to because it can't write to trans sessions yet -->
<!-- The only other use case is if you want to store the result of a forward in the raw logs -->
<stream id="dummy" type="local">
<log>false</log> <!-- No use storing the data -->
</stream>
</streams>
</dcafs><tasks>
<!-- And the relevant part of the dicer taskmanager -->
<task id="rolld20s" output="stream:dummy" trigger="interval:1s">d20:@rand20</task>
<!-- @rand20 will be replaced with a random number from 1 to 20, similarly @rand6,@rand100 exist -->
</tasks>Just like raw:dice the data received on a trans session can be used as a source trans:transtest.
Would be the logical next part to explain... but this goes beyond the 'getting started' idea of this guide. Check the reference guide instead.
This component is meant to track and respond to certain events, just like everything else it's controlled through cmd's so anything that can trigger a cmd can raise an issue.
Advantage of using an issue:
- The start and stop condition can be apart so that it won't toggle if it's around 10 or 20 degrees.
- The amount of occurrences and total active time of an issue is recorded.
All the nodes used, an issue looks like this
<issues>
<!-- Issue for the hot pump -->
<issue id="issueid" message="Desciption of what the issue is">
<!-- Either a single test -->
<test>number above 10 and below 20</test> <!-- When this is true, do the start if false the stop -->
<!-- Or a different test for start & stop -->
<startif>number above 20</startif> <!-- When this is true, do the start if the issue isn't active then activate it -->
<stopif>number below 10</stopif> <!-- When this is true, do a stop once if the issue is active and deactivate it-->
<!-- And the commands to run if the status changed -->
<cmd when="start">flags:raise,issueacive</cmd> <!-- The command to run when the issue is started/activated -->
<cmd when="stop">flags:lower,issueacive</cmd> <!-- The command to run when the issue is stopped/resolved -->
<!-- Multiple cmd's with the same when are allowed -->
</issue>
</issues>The issue has various commands:
-
issue:?Can a list of all the commands -
issue:test,idRun the test or startif/stopif -
issue:start,idStart the given issue -
issue:stop,idStop the given issue
This chapter will (eventually) contain multiple simulations that will be used to explain and show the stuff seen up till now with additional functionality of those parts added. There are two options, either try to solve these yourself or follow the steps explained.
In contrast to the previous diceroller the goal this time is to not cheat...
The first simulation is a 'simple' pump.
Settings file & tm script can be found here extract this to the folder that contains the .jar.
The properties:
- Warms up 1°C/s while active and keeps heating up till it breaks (at a measly 50°C)
- Prefers to stay between about 10°C and 25°C
- Has a good cooler that cools 2°C/s but lacks any safety feature
- When idle the pump slowly heats up/cools down to ambient temperature
- Ambient will slowly change towards the pump temperature (and faster if far off)
- Ambient will try to get to 20°C
- Data format: pump:active/idle/broken,cooler:active/idle/broken,temp:xx.x,ambient:xx.x
Below is the settings file to start from (included in the earlier linked zip).
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<dcafs>
<settings>
<mode>normal</mode>
<!-- Settings related to the telnet server -->
<telnet port="23" title="DCAFS_pump_scenario"/>
<!-- The simulation scripts, don't alter or look at it -->
<taskmanager id="pump">tmscripts\pump.xml</taskmanager>
</settings>
<!-- This is part of the dummy, don't change it -->
<streams>
<!-- connection to the pump -->
<stream id="pump" type="local">
</stream>
</streams>
</dcafs>The goals:
a. Process the data
b. Make sure the cooler is activated and stopped on time
c. Keep track of the times the cooler is activated and for how long
Open up two sessions again, one will be used to show incoming data and the other to run commands in.
Let's look at the data using raw:pump, should be something like this:
pump:idle,cooler:idle,temp:20.0,ambient:20.0
So the three states are idle,active,broken.
Next up is processing it, add a datapath with the id proc that has:
- editor node to alter the received states to numbers, and : to , for easier generic use
- generic to write those numbers to realvals
- 2x integer (pump_state and pump_cooler)
- 2x real (pump_temp,pump_ambient)
This can be partially done with the command pf:add,pump,raw:pump,eeeeiirr in which:
- pf:add is the command
- proc is the id
- raw:pump is the src
- eeeeiirr => Editor with 4 edits, generic with integer+integer+real+real
The result:
<path delimiter="," id="pump" src="raw:pump"> <!-- Note, these are always ordered -->
<editor>
<edit type="">.</edit>
<edit type="">.</edit>
<edit type="">.</edit>
<edit type="">.</edit>
</editor>
<generic id="pump">
<int index="1">pump_</int>
<int index="2">pump_</int>
<real index="3">pump_</real>
<real index="4">pump_</real>
</generic>
</path>So now to fill it in:
<paths>
<path delimiter="," id="pump" src="raw:pump" >
<editor>
<edit find=":" type="replace">,</edit> <!-- First replace the : with , -->
<edit find="active" type="replace">1</edit> <!-- then replace the word active with 1 -->
<edit find="idle" type="replace">0</edit> <!-- then replace the word idle with 0 -->
<edit find="broken" type="replace">-1</edit> <!-- then replace the word broken with -1 -->
</editor>
<generic id="pump">
<int index="1">pump_state</int>
<int index="3">pump_cooler</int>
<real index="5">pump_temp</real>
<real index="7">pump_ambient</real>
</generic>
</path>
</paths>