
NOTE: As of 19 Feb 2019, I have shut down the server that sends the predictions from the models due to the cost of maintaining the project. If you are interested in seeing this project live, feel free to run a local copy of the server on your system and modify the Chrome extension, or contact me.
r/eveal is a Chrome extension to enhance the user experience on Reddit by helping users
discover new communities based on the content they are submitting or viewing.
Reddit is a social media site where users engage in discussions in communities called
subreddits, often prefixed with r/. However, it's difficult to weed
through all of the 130,000+ active subreddits out there and find new communities other
than the most popular ones. Additionally many subreddits have strict moderation and
rules on what content they accept. Mods waste a lot of time removing posts and users can
get frustrated.
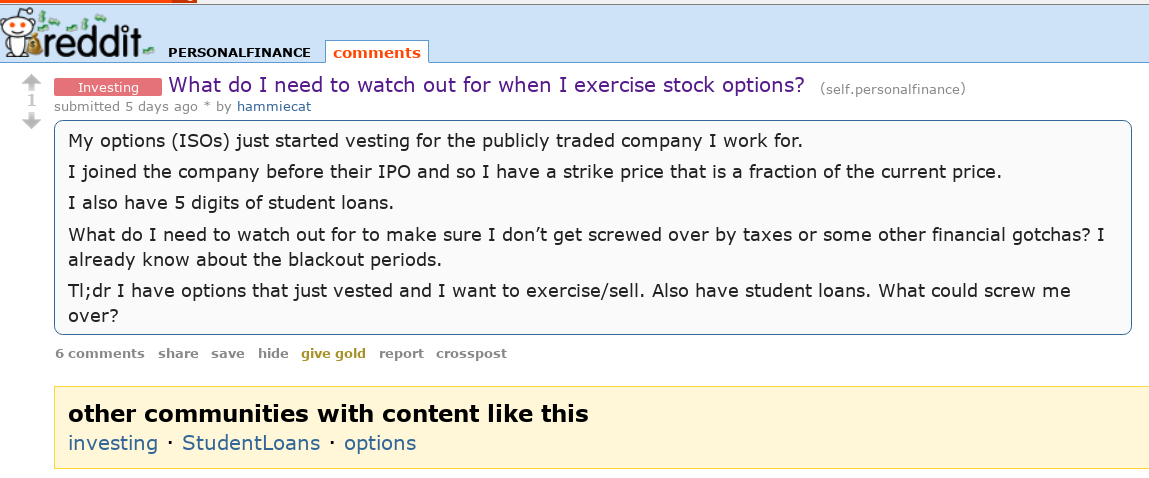
This extension adds a new information box underneath the submission form, showing communities related to the content being typed into the text box. Users will discover new communities related to what they are interested in. Additionally a new information box lists communities related to posts the user is viewing.
After cloning the repository, go to chrome://extensions in Chrome. Then select Load unpacked. Navigate to the cloned repository and select the directory
chrome_extension.
After installing the Chrome extension simply visit Reddit and prepare to submit your text post from any subreddit or from here. While typing in your new submission, subreddits with similar content will show up below the input.
If you want to submit your content to one of those subreddits, click the link indicating the subreddit and a new window with your post content will popup where you can submit your content!
Suggestions of similar communities of content you view will also be shown automatically.
Note: The extension does not work on the redesigned Reddit interface. Ensure that the checkbox "Use the redesign as my default experience" is unchecked on your preferences page.
There are some advanced options available to tune how many suggestions are displayed. By default, a maximum of 3 predictions are displayed per model for a total of 9 maximum predictions. There is also a threshold that limits the predictions, which can be adjusted. By making the threshold lower you are saying that you want to see classes with low confidence predictions. A higher threshold only shows highly confident predictions. This confidence is based on the distance to the separating hyperplane. In some cases, there are no highly confident predictions, and no communities will be displayed for that model.
Supervised learning models were trained on subsets of the May 2018 Reddit data corpus found here. I removed all over-18 communities and posts and only trained on "self text" posts that were not deleted or removed. I used three models for three different tiers of subreddits based on the number of subscribers of those subreddits ("popular", "kinda popular", "not-so-popular").
I used a bag-of-words approach using scikit-learn's HashingVectorizer with 218 features and L1 normalization of the word counts (that is, word frequencies were used). The text of the title and of the post itself were used in this feature vectorization. The subreddit names were used as the labels. I attempted using out-of-core Naive Bayes, but ran into memory usage when training, even on the reduced training sets. I also tried Logistic Regression with Stochastic Gradient Descent (SGD) but the resulting models took up several GB of disk space.
In the end, SGD with Support Vector Machine was used for classifying the posts in all of the models due to its low latency in predicting and memory efficiency. I selected a regularization parameter based on validation set performance from a grid search. Additionally I held out a test set to evaluate the performance of the selected model. Each model had between .5 and .6 mean accuracy in predicting the ground truth from the 550-600 classes. I then retrained the models on all the data I had and put those in production on AWS.