Delta lake is an open-source project that enables building a Lakehouse architecture on top of existing storage systems such as S3, ADLS, GCS, and HDFS.
Fase 1: Configurações dos dados da base do Kaggle: https://raw.githubusercontent.com/tianyigu/Lord_of_the_ring_project/master/LOTR_code/script.csv
Dados Relacionados a Trilogia da Franquia "O Senhor Dos Anéis", os dados em questão são trechos retirados das falas ditas por seus personagem nessa trilogia.
Nessa Análise estaremos realizando a tradução desses trechos para o português, verificando qual personagem possui maior e a menor quantidade de diálogo.
São realizadas etapas de processamento em que são removidas colunas desnecessárias e preparação de tabelas com join para MDW modelagem com dados normalizados em formatos de conjunto de dados.
Teremos a responsabilidade de enriquecer os dados, neste processo é onde tratamos os dados e refinamos para a área de negócios ou quem irá consumir os dados.

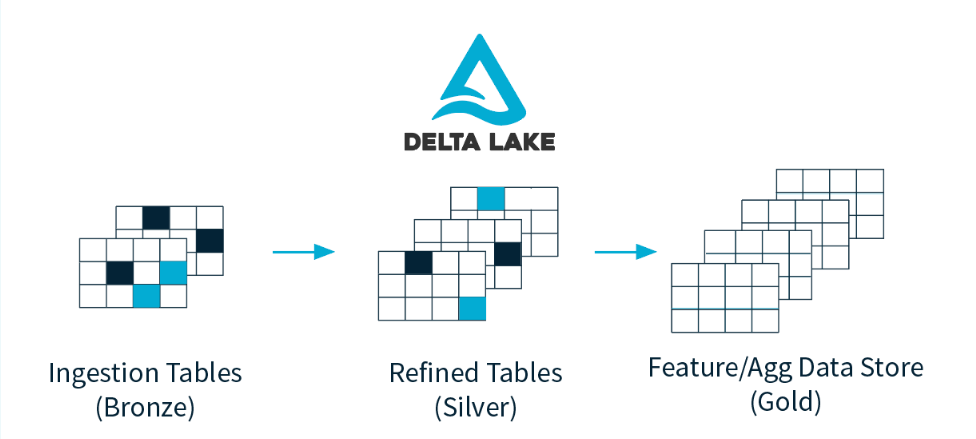
No projeto iremos lê os dados de um sistema de arquivos chamado landing-zone usando dependências de deltalake, que são pacotes .jar e estarão escritos na configuração de sessão do spark, com o qual é possível usar o framework Delta Lake. Após a execução deste script, os dados serão escritos no diretório passado no código, já dentro da tabela de escrita, será escrito um diretório chamado _delta_log, que é responsável por armazenar arquivos incrementais nos metadados da tabela, será algo como 000000000000000000000.json, 000000000000000000001.json...
O arquivo Json na pasta _delta_log terá as informações como add/remove parquet files (for Atomicity), stats (for optimized performance & data skipping), partitionBy for partition pruning), readVersions(for time travel), commitInfo(for audit).
- Pyspark - 3.1.1
- Deltalake
- Python 3.10
- @carlosbpy - Idea & Initial work
- @wuldson - Case, Study & Pratice