This repository contains the code for the paper Large Language Models Can Learn Temporal Reasoning.
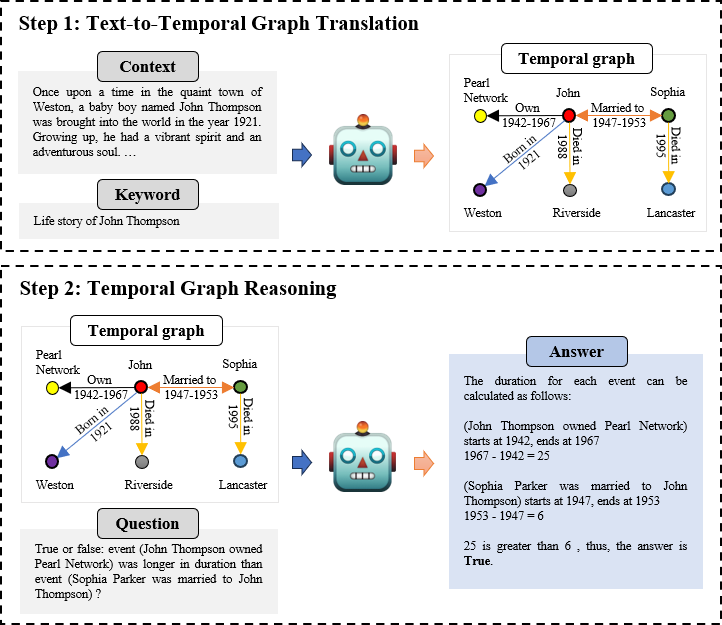
Our framework (TG-LLM) performs temporal reasoning in two steps: 1) Text-to-Temporal Graph translation: generate (relevant) temporal graph given the context and keyword (extracted from questions); 2) Temporal Graph Reasoning: perform deliberate Chain-of-Thought reasoning over the temporal graph.
We use Hugging Face platform to load the Llama2 model family. Make sure you have an account (Guidance).
The structure of the file folder should be like
TG-LLM/
│
├── materials/
│
├── model_weights/
│
├── results/
│
└── src/# git clone this repo
# create a new environment with anaconda and install the necessary Python packages
# install hugging face packages to load Llama2 models and datasets
# create the folders
cd TG-LLM
mkdir model_weights
mkdir results
cd src- Step 1: text-to-temporal graph translation
# Train and test on TGQA dataset
python SFT_with_LoRA_text_to_TG_Trans.py --dataset TGQA --train --print_prompt
python SFT_with_LoRA_text_to_TG_Trans.py --dataset TGQA --test --ICL --print_prompt
# Train and test on TimeQA dataset (Since some stories in TimeQA and TempReason are too long to feed into Llama2 (max_context_len: 4096), it is recommended to shorten the story.)
python SFT_with_LoRA_text_to_TG_Trans.py --dataset TimeQA --train --print_prompt --shorten_story
python SFT_with_LoRA_text_to_TG_Trans.py --dataset TimeQA --test --ICL --print_prompt --shorten_story
# Train on TGQA, test on TimeQA
python SFT_with_LoRA_text_to_TG_Trans.py --dataset TGQA --train --transferred_dataset TimeQA --print_prompt
python SFT_with_LoRA_text_to_TG_Trans.py --dataset TimeQA --test --shorten_story --ICL --print_prompt --transferred- Step 2: temporal graph reasoning
# Obtain CoT sampling prob
python CoT_bootstrap.py --dataset TGQA --print_prompt
# Train and test on TGQA dataset
python SFT_with_LoRA_TG_Reasoning.py --dataset TGQA --train --CoT_bs --data_aug --print_prompt
python SFT_with_LoRA_TG_Reasoning.py --dataset TGQA --test --ICL --print_prompt
# To obtain inference results based on perplexity
python SFT_with_LoRA_TG_Reasoning_ppl.py --dataset TGQA --ICL --print_prompt- Use in-context learning only
# Test on TGQA with Llama2-13b with ICL only
python Inference_in_context_learning.py --dataset TGQA --model Llama2-13b --CoT --ICL --print_prompt
# To obtain inference results based on perplexity
python Inference_in_context_learning_ppl.py --dataset TGQA --model Llama2-13b --CoT --ICL --print_prompt- Use SFT with vanilla CoT (story, question, CoT, answer)
# Train and test on TGQA dataset
python SFT_with_LoRA_TG_Reasoning.py --dataset TGQA --train --print_prompt --no_TG
python SFT_with_LoRA_TG_Reasoning.py --dataset TGQA --test --ICL --print_prompt --no_TG
# To obtain inference results based on perplexity
python SFT_with_LoRA_TG_Reasoning_ppl.py --dataset TGQA --ICL --print_prompt --no_TG# To evaluate our framework
python Evaluation.py --dataset TGQA --model Llama2-13b --SFT
# To evaluate other leading LLMs with ICL only
python Evaluation.py --dataset TGQA --model Llama2-13b --ICL_only --CoT
# To evaluate other leading LLMs with SFT on vanilla CoT
python Evaluation.py --dataset TGQA --model Llama2-13b --SFT --no_TGThe original format used in the paper is plain text. We also provide the option of JSON which is much easier to parse and doesn't hurt the performance much. Please use the command --prompt_format to change the format seamlessly.
All the datasets (TGQA, TimeQA, TempReason) can be found here.
To download the dataset, install Huggingface Datasets and then use the following command:
from datasets import load_dataset
dataset = load_dataset("sxiong/TGQA", "TGQA_Story_TG_Trans") # Six configs available: "TGQA_Story_TG_Trans", "TGQA_TGR", "TempReason_Story_TG_Trans", "TempReason_TGR", "TimeQA_Story_TG_Trans", "TimeQA_TGR"
print(dataset) # Print dataset to see the statistics and available splits
split = dataset['train'] # Multiple splits available: "train", "val", "test"The default training/inference arguments are for a single A100 (GPU memory: 80G). If you have multiple GPUs, the training process can be accelerated in a distributed way. Here we recommend the library of DeepSpeed [docs].
Also, you can accelerate the inference with multiple GPUs [src/Example_accelerate_inference.py].
If you have any inquiries, please feel free to raise an issue or reach out to sxiong45@gatech.edu.
@inproceedings{xiong-etal-2024-large,
title = "Large Language Models Can Learn Temporal Reasoning",
author = "Xiong, Siheng and
Payani, Ali and
Kompella, Ramana and
Fekri, Faramarz",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.563",
doi = "10.18653/v1/2024.acl-long.563",
pages = "10452--10470"
}