the Reforcement Learning Algorithm used on a maze problem with Temporal-Gradient-Correction (TGC)
This projects base on an environment such that an explorer try to find the key firstly then escape from a maze, and provides several RL algorithms in the algorithm folder like SARSA, Q-learning, Monte-Carlo, as well as some updated algorithms.
The Simulation.py, define a class to simulate the process of explore
The env_maze.py provides a class to build a model with specific details of a maze and different feature mappings to grid which achieve the function approximation avaliable (not only table look-up).
The maze_sim.py, firstly gives a class MazeSim which define the details of explore such as relative reward and steps. Secondly, MazeFeatures class use the feature mapping on the grid.
With large size maze, the sarsa and q-learning will show disconvergence problem and by analysis, it could be overcomed by gradient descent correction (see the pdf file Comparison between conventional TD algorithm and TD with gradient descent).
See the comparsion below (10*10 maze)
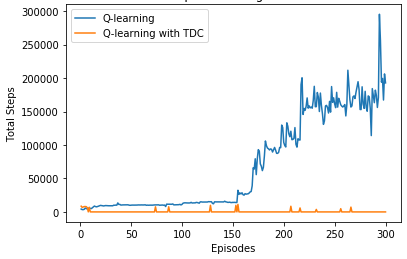
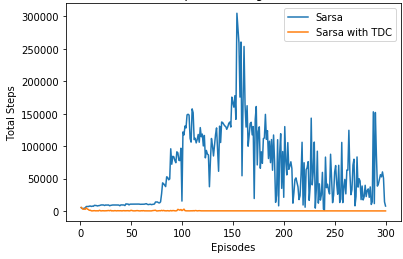
A solution to this maze problem by SARSA with TDC (Green Block means start and end, Yellow Block means the key)
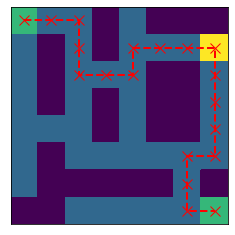
This maze background is quite easy, the RL could be achieved in many complex cases like automation, navigation, game and so on.