Diagnosis Guide
CAUTION: This document is generated from {X}fm source and should **not ** be hand edited. Any modifications made to this file will certainly be overlaid by subsequent revisions. The proper way of maintaining the document is to modify the source file(s) in the repo, and generating the desired .pdf or .md versions of the document using {X}fm.
Attempting to blame, or rule out, VFd as the cause of communications problems can be tricky. This guide should provide some assistance with determining whether or not VFd is functioning as expected, might be contributing to, or even the entire cause of, the observed problem.
Using the component diagram in figure 1 as an illustration, this document uses the following terminology.
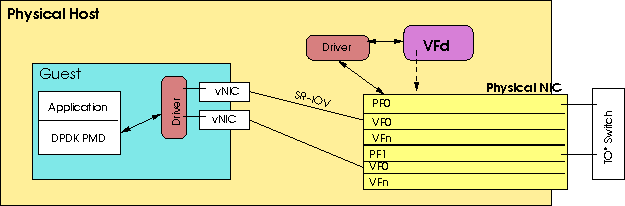
Figure 1: Relationship of guests, PFs, VFs, and VFd.
Application: The application which runs inside of a _ guest_ and uses one or more of the guest's SR-IOV ports to send and/or receive network traffic.
DPDK: Dataplane Development Kit. A library which provides direct and easy programmatic access to one or more NICs. The NICs must be bound to DPDK compatible device drivers such as igb_uio or vfio-pci.
Driver: A low level software module which is loaded by the kernel and is used as an interface to a piece of hardware. In the case of the NICs these provide some level of configuration and control of the NIC.
Guest: A virtual machine, or container, which has been given one or more SR-IOV device that is under the control of VFd.
NIC: Network interface card. In the VFd world, these NICs are capable of having VFs configured which allow multiple guests to use the same physical device, with the appearance of having solitary access to, and complete control of the device, without the hypervisor layer emulation of a NIC.
PF: Physical function. The firmware[1] on a NIC which provides the functionality that is applicable to the NIC itself. There is one PF per port on a NIC. (See VF.)
PMD: Poll Mode Driver. A component within the DPDK library which provides fast device reading to the application by constantly polling the network interface for packets. The PMD method of operation is the the opposite of interrupt driven where the application would "sleep" until notified by the operating system that a packet, or packets, are ready to receive.
Rx: Receipt; packets received from the wire through the NIC and into the guest application.
Spoof: An attempt to send a packet with a VLAN ID or MAC address in the packet which is not in the white list for the VF.
SR-IOV: Single Root, I/O Virtualisation. The ability to provide direct input/output access to a single PCI device (a NIC, or video card) from multiple processes or guests concurrently without the need to provide an emulation of the device in the hypervisor. Direct i/o through an SR-IOV device is much more efficient, therefore it provides much higher data transfer rates which can be very close to running the application on bare-metal rather than inside of a guest.
Tx: Transmission; packets sent from the guest through the NIC and onto the wire.
VF: Virtual function. The firmware on a NIC which provides the ability to simulate multiple NICs. Depending on the NIC type, there could be as many as 128 VFs configured for each PF. Usually, there are 32 or 64 configured.
Whitelist: A list of things (usually VLAN IDs or MACs) which are permitted to be used for sending packets through an SR-IOV port.
VFd is a configuration and policy enforcement daemon. It is responsible for reading the VF configurations supplied by a virtualisation manager (e.g. Openstack) providing some sanity checking, then communicating the VF configuration to the NIC. As a part of the sanity check, VFd is responsible for ensuring that the configurations are not in conflict with each other. VFd also allows the configurations to be dynamically added and removed, and provides for real-time policy enforcement when a guest attempts to change the VF (e.g. set a different MTU, add a VLAN ID, or change the associated MAC address). VFd is a necessary component as some of the drivers, ixgbe in particular, do not provide any mechanism to configure all of the NIC's features, nor do they provide any means for real-time policy enforcement.
VFd is not involved with any packets or flows; once a VF is configured, and the guest has performed any configuration that requires VFd acknowledgement or approval, VFd is not involved with the operation of the VF.
For some requests that the guest makes with respect to configuring the network "hardware" visible in the guest, VFd is asked by the driver to approve or reject the request. The following are the requests that the driver should send to VFd, and the approval criteria that VFd implements.
VFd assumes that the TO* switches are configured such that
all traffic must be tagged with VLAN IDs and as such it is
permissible for a guest to set any MAC address that it
chooses. Thus, VFd will approve any set default MAC request
unless that MAC address has already been assigned to another
VF on the same PF. When the requested MAC address is already
assigned to a PF, the request is rejected. After approval,
the guest should see the MAC when using ifconfig
or ip commands, and should be able to
send packets with the address as the source in the L2 header.
Similar to setting the default MAC address, a guest may send a series of MAC addresses which are added as a set of alias addresses. VFd will reject the request if any of the addresses is already assigned to another VF on the same PF and will approve the request otherwise. After the whitelist has been approved for the VF, any packets arriving with one of the addresses as the destination (L2) will be forwarded to the guest, and the guest should be able to use any of the addresses as the source MAC.
With respect to setting a VLAN ID, the guest will be permitted to change the VLAN ID only to one of the IDs that is listed in the VF configuration provided by the virtualisation manager (e.g. Openstack). If a requested ID is not in the list, the request is denied.
This request is always approved by VFd.
The driver running on the physical host must be a DPDK
compatible driver which provides for the communication
between VFd and the driver. The igb_uio driver
is used to configure the VFs on each PF during system
initialisation. On older HP hardware the use of this driver
caused DMAR errors, which resulted in some installations
opting to unload it and load the vfio-pci
driver after VFs were created (the vfio-pci driver does not
have the ability to create VFs). We do not recommend this
practice as it potentially can lead to memory corruption
issues; memory allocated by the igb_uio driver may be
referenced after the driver is unloaded causing unpredictable
problems and possibly system panics[2].
While VFd is not actively in the path of network traffic, VFd must be thought of as a driver and given the same considerations as are given when it is necessary to reload any kernel driver. Stopping VFd has the same effect as would be experienced should the NIC driver be unloaded: the NIC in the guest will appear to go down.
It is entirely possible to stop and start VFd without impacting the guest or applications running in the guest. However, this requires that the drivers and/or applications in the guest properly detect the NIC state change and then do the right thing when it is available again. Our experience is that some kernel drivers behave this way, but most DPDK applications do not and at a minimum the applications need to be restarted after VFd is running again.
From an operational perspective, most guests are likely to be black boxes , thus their ability to properly react to a VFd restart is unknown, so the policy that most installations have implemented is to completely stop all guests before cycling VFd, and to force guests to be stopped and restarted following an unexpected VFd outage. This is certainly the "safest" approach.
Because the physical host driver for a VFd managed SR-IOV NIC is a DPDK based driver, support for all of the convenient tools (e.g. tcpdump) is not available as it is when using a kernel driver. There are some tools and/or techniques which can be used when determining the cause of a guest's inability to communicate over one or more network interfaces.
Using the iplex show all command on the
physical host causes the current NIC counter information to
be generated. Executing this command several times, over the
period of ten or twenty seconds will indicate whether or not
any traffic is flowing (either away from the guest, toward
the guest, or both) and can also indicate whether or not
there are issues with spoofing, or the possibility of a
slow application.
VFd will only list stats for a VF when it has an active
configuration as submitted by the virtualisation manager (or
manually for debugging). Therefore, even if there are 32 VFs
configured for each PF, the VFs displayed by the show
all command will likely be a subset of those 32. If
there is a question as to whether or not the correct number
of VFs were created under a PF, and/or if the correct driver
is bound to any VF, the dpdk_nic_bind command,
with the -s option, can be used to list all
information about networking devices on the physical host.
For DPDK releases starting with the November of 2017 library,
the command name is dpdk-devbind.py.
A spoofed packet is dropped by the NIC and the spoof
counter is increased. The NIC views a spoofed packet
as a packet containing an L2 source address which does not
match any address associated with the VF, or that has a VLAN
ID which does not match any ID associated with the VF. Most
NICs do not distinguish between the types of spoof drops, but
when they are occurring in large numbers it is usually an
indication that the packets being sent by the guest are
invalid (at least with regard to the current configuration.
The drop counter is maintained by the NIC for each VF and reflects the number of packets that the NIC was unable to deliver to the VF because there were no buffers in the receive ring. If this number is large, and/or is continually increasing, the indication is that the application is not able to keep up with the influx of packets. The application's inability to keep pace could be for any number of reasons including:
-
The application is spending too many cycles processing each CPU.
-
The CPUs that the application is pinned to is on a NUMA that is not matched to the NIC.
-
The input to the guest is being mirrored to another VF and the process receiving the mirrored packets is not able to keep up.
Occasionally we have observed the case where all other guests
are functioning normally and the problematic guest begins to
work only when the device driver in the guest is unloaded and
reloaded. This tends only to be the case when the kernel
driver (e.g. ixgbevf) is being used in the guest. The correct
state for the VF is reported by the NIC through iplex
show all , but Rx coutners do not increase for the VF
when traffic is sent.
Some NICs provide the ability to mirror (duplicate) packets to a second VF on the same PF[3]. VFd supports enableing the mirroring of packets such that all inbound (received), or outbound (transmitted) packets for the VF are written to the target VF. It may also be possible to mirror traffic in both directions, but this is dependent on the NIC that is involved.
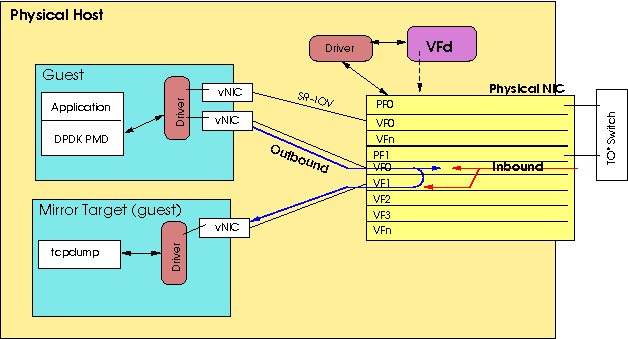
Figure 2: Guest relationships to captured mirrored traffic.
Mirroring packets can be a way to verify that the header (either L2 or L3) in the packets is as expected, and that traffic is indeed arriving at, or being sent from, the guest. Most mirroring has the caveat that a packet will only be mirrored if it would be written to the VF (dropped packets, or packets that don't have a matching VLAN ID won't be seen on the mirror). For outbound packets, only packets that the NIC would write to the wire are mirrored; spoofed packets are not sent to the mirror target VF. This somewhat limits the usefulness of mirroring, but doesn't make it worthless.
Mirroring is also somewhat costly. If the application
processing the mirrored packets is not efficient, then the
application being monitored will be impacted and could result
in packet loss. It is recommended that tcpdump
be used to capture the raw data, and that any packet
formatting be done after the fact.
It is also possible to attach a kernel driver on the physical
host to a VF which allows tcpdump, or other
capture application, to be run directly on the bare metal.
The advantage to this is that there is no extra setup
required to forcing a guest to start on the affected physical
host. However, the target VF must be configured by VFd, and
that will likely require the manual generation of a
configuration file, and adding it to VFd in the same manner
that the virtualisation manager does.
One extremely important diagnostic tool is the ability to monitor traffic at the TO* switch. This includes the ability to verify whether or not packets to the troubled PF are flowing in either direction. If traffic is received from the physical host, then the issue is likely not at all related to the guest, NIC, or VFd. From a reverse direction point of view, if traffic is being forwarded to the physical host, yet not arriving at the guest, then the problem is likely isolated to the physical host, however if no traffic with the VF's MAC address is observed on the switch, the problem is not NIC/VFd. related.
When a guest application is experiencing unexpected network behaviour it is desirable to verify that VFd isn't the cause of the problem. In general the ability of VFd to affect network traffic in a negative way can be viewed as an all or nothing situation; when VFd has buggered things, nothing at all related to the NIC(s) works, and if anything realted to the NIC(s) is working the cause of the problem is very unlikely to be the fault of VFd. This isn't always the case, but happens enough to make this generalisation.
When attempting to determine whether or not VFd's behaviour is acceptable the following areas and/or actions should be considered.
The VFd log (usually written into the /var/log/vfd directory)
should be searched for any of these strings: CRI, ERR,
or WRN.
CRI: These are critical errors which are generally so severe that VFd cannot continue to successfully operate. It would be expected that if any critical error is found in the log that VFd will not actually be running. Critical errors suggest that immediate action needs to be taken.
ERR: Errors generally indicate a situation where VFd felt that it was able to continue, but actual behaviour of the NIC or a configuration of a VF might not be as expected. Errors which are related to an external request (such as those induced by Openstack's attempt to add or delete a configuration) are not logged with this tag. It is expected that an externally induced error will be reported by the requestor via their logging system, and are not a concern of VFd. Regular errors do not require immediate action, but should be looked at within 48 hours to ensure correctness.
WRN: Warnings are logged with this tag. They indicate unexpected events which are not considered to be problematic to the continued operation of VFd, but should be investigated at some point in the future by operational staff.
Normally, VFd executed with a log level of 1 which keeps the amount of information written to the log to a minimum of errors, warnings, and limited diagnostic information. Once a problem is suspected, it is recommended that the log level be increased to 2 as this will provide more details in the log. The following command can be used to adjust the log level without the need to change the configuration file:
sudo iplex verbose --loglevel=2
VFd supports log levels of 3 and 4, however at log level 4 (a programmer's debugging mode) the amount of information written to the log can be so large as to make it impossible to easily diagnose a problem.
If the spoof count for any PF continues to increase as the affected guest(s) send traffic, this is a good indication that the packets being generated by the application are not correct. The NIC will drop the packet, and increase the spoof counter, when the packet has a VLAN ID which doesn't match any configured in the VF configuration file, and/or the source MAC address is not one that has been set in the VF configuration or explicitly by the guest through a set default mac, or set mac white list request.
The link state presented by the iplex show all
command should be examined for the affected PF(s).
The PF states will show DOWN either when the
physical connection on the port is disconnected, or when the
port on the other side of the wire (at the TO* switch) is
down. When this status shows down, a physical inspection at
both ends should be made before any further diagnostic
efforts are expended.
If the VF state shows DOWN then the NIC/driver
believes that the guest has executed the equivalent of an
ifconfig xxx down command, or when a DPDK
driver is being used in the guest, the DPDK application is
not running, or has not opened the device.
Using the count information produced by several iplex
show all commands over the span of twenty or thirty
seconds can determine whether or not any traffic is flowing
over the VFs under VFd control. When the Tx and Rx counters
for any VF are increasing it is generally an indication
that the NIC is behaving as expected.
If traffic is observed on the NIC, check the traffic counters for the VF(s) which are attached to the problematic guest. If the Rx and Tx counters for the these VF(s) are increasing, this is almost always an indication that the problem lies elsewhere (routing, LAG configuration, duplicate MAC addresses, etc.).
The increasing Tx counter indicates that packets are received from the guest by the NIC, are not spoofed, and are being written out onto the wire. It has never been observed that the Tx counter was increased without a transmission onto the wire.
The increase of Rx counts indicates that packets are being received with a matching destination MAC address and VLAN ID for the PF, and that the NIC has successfully placed the packet into a buffer available for the guest to receive. If the Rx counter for the VF is not increasing one, or more, of the following could be happening:
-
Packets are not being received from the TO* switch with the (any) MAC addres(es) configured on the VF.
-
The VLAN ID in the pacekt(s) is not correct.
-
The application in the guest has wedged and is not removing any packets thus blocking the ability to transfer packets (error count increasing) into the application. It is possible that this kind of block could affect other VFs and not just the wedged VF.
The first two situations can be verified by capturing packets at the TO* switch; it will not be possible to capture this kind of loss with a VF mirror. The third situation is fairly unlikely and examination of the application would need to take place to verify if this were the case.
Should the incorrect VLAN ID(s) or MAC address(es) be configured for a VF, the result would be some or all packets will not be delivered to the guest. Verifying that the information that is being configured requires checking in several places as it is possible to set these from the VF's configuration file, and it's also possible for the guest to change these settings.
The VF config file (/var/lib/vfd/config/.json) will contain an array of VLAN IDs that the guest is permitted to use. This list should be verified to match, or be in the range of, the VLAN ID(s) configured on the TO switch. In addition, an array of MAC addresses may be supplied in the configuration file. If MAC addresses are supplied, verify that they are correct.
It is also important to verify what VFd has "pushed" out to
the NIC, and/or what the guest has requested that might not
be defined in, or is overriding the contents of the
configuration file. The iplex dump command can
be used to request that VFd dump current settings into the
log file. For each PF/VF combination, several important lines
are generated in the log which show the MAC addresses which
are currently set for each, as well as the VLAN IDs. Figure 3
contains one such set of log messages[4] showing the current
configuration settings (truncated for presentation), and the
list of VLAN IDs and MAC addresses which are currently in
use.
[1] dump: port: 0 vf: 4 updated: 0 strip: 1 insert: 1 vlan_aspoof: 1...
[2] dump: pf/vf: 0/4 vlan[0] 21
[2] dump: pf/vf: 0/4 mac[1] fa:ce:ed:09:00:04
Figure 3: Sample dump output for PF=0, VF=4.
Depending on the nature of the guest application, the MAC address actually configured on the VF might not match what exists in the configuration file. This is normal behaviour when the guest sets one or more MAC addresses using either a set default mac or a set mac whitelist operation on the device. In either case, VFd will override the address(es) set in the configuration file and use what is provided by the guest when pushing the configuration to the NIC for the PF. When this happens, VFd generates various log messages indicating the addresses that are being added and deleted. (The nature of some of the guest drivers cause this sequence of messages to be repeated with any change it makes to the white list, so it is not uncommon to see multiple sets of these messages during guest initialisation, at the time the DPDK application is started in the guest, or even both.) Figure 4 contains one PF/VF's set of messages generated when the guest set a white list of MAC addresses.
[1] set macvlan event received with address of 0s: clearing all but default MAC: pf/vf=0/6
[1] clearing macs for pf/vf=0/6 use_rand=0 fm=1 nm=4 si=5
[1] set macvlan event received: pf/vf=0/6 fa:ce:ed:09:9a:05 (responding proceed)
[1] set macvlan event received: pf/vf=0/6 fa:ce:ed:09:9b:05 (responding proceed)
[1] set macvlan event received: pf/vf=0/6 fa:ce:ed:09:9c:05 (responding proceed)
Figure 4: Sample log messages generated when a MAC white list is added for a VF.
The normal sequence of events initiated from the guest is to cause the list to be cleared, followed by the request to add one or more MAC addresses to the white list. The indication _ responding proceed_ in each of the final three messages indicate that VFd accepted the address and added it (the address was not duplicated).
[1] setmac event approved for: port=0
[1] push_mac: default mac pushed onto head of list: pf/vf=0/6 fa:ce:ed:09:aa:07 num=4
[1] guest attempt to push mac address successful: fa:ce:ed:09:aa:07
Figure 5: Log messages generated during a successful set default mac request.
When a guest sets the default MAC address, as opposed to a
white list, the messages generated for a successfully
processed request are illustrated in figure 5. It should also
be noted that when a guest uses the set default request, that
the output from the an iplex dump command will
list this MAC address as element [0][5] as shown in figure 6
[2] dump: pf/vf: 0/6 mac[0] fa:ce:ed:09:aa:07
[2] dump: pf/vf: 0/6 mac[1] fa:ce:ed:09:01:05
[2] dump: pf/vf: 0/6 mac[2] fa:ce:ed:09:9c:05
Figure 6: MAC list when a default address has been set.
When a guest attempts to push a MAC address which is already in use by another VF on the same PF, the request will be negatively acknowledged, and VFd will generate one of the log messages in figure 7 depending on the actual request.
[1] can_add_mac: mac is already assigned to on port 0: fa:ce:de:09:00:01
[1] set macvlan event: add to vfd table rejected: pf/vf=0/6 fa:ce:de:09:00:01 (responding nop+nak)
Figure 7: Messages associated with failed MAC address attempts.
It is common for a guest driver and/or DPDK application to attempt to set a MAC address or white list several times. When this happens, VFd will log the attempt with a message that the address already exists in its list and that no action was needed. When this happens, VFd always responds with a positive acknowledgement to the request.
The following paragraphs describe some of the situations that have been observed, their symptoms with respect to VFd and what the final root cause of the issue turned out to be.
Surprisingly, this symptom covers a fair number of of the issues that we have helped to resolve. The usual complaint is that one or more of the following are happening:
- Pings from the guest work to some addresses but not all addresses.
- Pings from the guest don't work to a target address, but BGP can always establish a session.
- Neither pings from the guest, nor ssh sessions from the guest, to an address work.
- Pings from the guest work to an address, and occasionally ssh works to the address.
For all of these symptoms the root cause was a misconfigured switch (usually the switch connected to the physical host where the guest is running, or the switch directly adjacent to the target endpoint. Another cause which has generated some of the above symptoms was on several occasions a badly configured LAG between the physical host that the TO* switch. We also observed one case where the switch was configured with four links in the LAG, but only two were actually being supported by the application in the guest.
In all of these cases, an examination of the VFd "environment" showed that there were other guests operating normally over the same PFs as the affected guest was attempting to use. Further the affected guest's PF was always showing increasing Tx counters, and occasionally showing increasing Rx counters. Both of these observations indicated that the NIC was passing traffic as expected, and that the problem was likely not VFd or NIC related.
Especially in the case of link aggregation, a misconfiguration either in the switch, or the application's bonding of the interfaces visible in the guest, can easily produce the symptom of "it works sometimes, but not always," or "some things always work, but other things work partially or never." Typically the cause is that inbound traffic is being distributed by the TO* switch across the LAG and only a portion of the traffic is actually reaching the guest. Any time a guest's network traffic is problematic, and there is a LAG involved, we recommend doing the following things:
-
Verify that another guest is able to send traffic over the same PF through a single (non-LAG) connection to the switch. (Ensures that the NIC is passing traffic.
-
Ensure that the VLAN ID(s) configured for each of the VFs is/are correct.
-
Ensure that the MAC addresses in use on the VFs are correct (use iplex dump)
-
Break the bond in the guest and test the links individually.
Using VFd to configure and manage NICs has no effect on the ability of guest applications to transfer packets. We have measured applications transferring minimally sized packets (64 bytes) at a rate of approximately 14 million packets per second. Because VFd does not insert itself into the packet processing path, there is little chance that any performance issue is related to VFd. If a guest application experiences a drop in performance, and/or an unacceptable packet loss rate, it is most likely caused by one of the situations described in the next few paragraphs.
The use of flow control on the TO* switch does have the ability to negatively impact performance for all guests which are using the PF. We expect that flow control is disabled at the switch, and VFd configures the NIC to not support flow control. If flow control is enabled for the port(s) on the TO* switch, it is possible that this has a negative impact on the guest(s) application(s).
The majority of the time that guest performance drops (packets per second decreased and/or the loss rate increased), the cause is a CPU pinning issue for one or more of the vCPUs that the guest is using. Especially with DPDK applications being run in the guest, the vCPUs need to be pinned such that they do not collide with other guests, and in NUMA alignment with the NICs. Cross NUMA access to NIC buffers can place a significant latency on the overall packet rate through the guest.
There have been reports that the status of a VF shown in the
output of a show all command is incorrect with
respect to what is observed in the guest. Specifically, the
state shown in the output is DOWN yet the
guest (via an ifconfig or ip command) indicates that the
device is up. Attempts to cycle the device yield no change
in the output from show all.
In this case VFd is merely reporting on what the NIC believes
the status is; VFd does not actually take any action which
affects the state indication. The fact that the state does
not change indicates that there is a disconnect between the
guest driver and the driver on the physical host and that the
change in state inside of the guest is not being properly
communicated to the physical host driver. This can be
confirmed by looking at the VFd log; typically when a guest
puts a device into a down state, the physical driver
communicates the state change to VFd and there are a few
messages written to the VFd log file. Similarly, when the
device is returned to an UP state in the
guest, there will be a smattering of messages in the log. If
no messages are observed, then the driver on the physical
host is not receiving the state change from the guest and
thus is not communicating the change to VFd.
This particular symptom has only been observed on physical
hosts where the version of DPDK used to generate the
igb_uio driver was older than the version that VFd
was built with. This has been referred to as the mismatched
driver issue, and that has been blamed for several,
difficult to reproduce, issues such as the incorrect status
problem. The version of DPDK used to build VFd is recorded
and written to stdout when VFd is run with the -?
option on the command line; illustrated below:
VFd v2 +++940b375b2c0e2d79f767a31021a4f37a68bba8c6-notag build: Jul 12 2018 13:45:43
based on: DPDK 18.5.16
Figure 8: Some of the output from VFd's help request.
Should the version of the igb_uio driver (assumed to have created the VFs for each PF) be compiled from an older version of DPDK than is shown by the VFd help option, then the driver must be upgraded to completely rule out odd issues triggered because of the mismatch. While we haven't observed any issues when the driver is using a newer DPDK version, it makes good sense to keep them synchronised if at all possible.
Normally, once VFd has finished initialisation, its CPU utilisation will be less than 2%. When a configuration is added or deleted, or when processing PF driver requests, the usage might peak at 10 or 15% for a second or two. If CPU usage goes above 80%, and stays there for more than a few seconds, there is likely a guest application which is causing an excessive number of interrupts that are reaching the VFd interrupt handling thread.
This situation can be determined by executing a top
command with the -H option on the VFd
process id (e.g. top -H -P 43086). Figure 9 shows the output
from a top command with the expected threads associated with
VFd.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
43086 root 20 0 0.125t 13036 7612 S 0.3 0.0 1:03.63 vfd
43086 root 20 0 0.125t 13036 7612 S 0.0 0.0 0:00.00 rte_mp_handle
43086 root 20 0 0.125t 13036 7612 S 0.0 0.0 0:00.00 rte_mp_async
43086 root 20 0 0.125t 13036 7612 S 0.0 0.0 0:00.04 eal-intr-thread
43086 root 20 0 0.125t 13036 7612 S 0.0 0.0 0:11.50 vfd-rq
Figure 9: Top output showing the VFd interrupt thread.
When an overactive guest application is running wild, the eal-intr-thread CPU will likely be close to 100% and certainly will be greater than 20%. VFd monitors its CPU utilisation and will write error messages to the log when it detects a state like this.
The problem which causes this is usually a guest DPDK application which is checking the link state more often than is practical. Each hard link state check (there is a soft check which avoids the problem) causes the driver to trigger an request to VFd. The overload of requests (we've observed several hundreds of thousands per second) cause VFd's tread to spend CPU cycles checking the request type (one which actually never reaches VFd code), and ignoring it.
The fix is to have the application convert the majority of the link status check calls to use the no wait option. We assume that a badly behaving application will be noticed long before it reaches a production environment, however it is possible that a bug in the application could cause it to start generating link status checks unexpectedly which is why we've included this section.
[1] We use firmware to mean a combination of NIC registers which provide the interface to the hardware for the driver, and the actual firmware which might provide on NIC processing.
[2] The issues associated with the unloading of a driver which created VFs, if the VFs were allowed to remain, are so potentially harmful that in 2016 Intel changed the behaviour of the ixgbe driver such that the VFs are destroyed when the driver is unloaded. This behaviour isn't implemented by the igb_uio driver (maintained as a part of the DPDK source), but we expect that some day it might be.
[3] Please refer to the VFd Debugging Tricks document for details on creating mirrors: https://github.com/att/vfd/wiki/Debugging-Tricks
[4] Log messages are shown without leading timestamp information to simplify things. The verbosity indicator (e.g. [1]) is left to show the loglevel setting that causes the message to be generated.
[5] A bug in VFd for builds prior to June 2018 causes the list to show an empty MAC address at element [1] when a default MAC is set. This results in an error in the log when VFd tried to push it to the NIC, but there was no ill effect to this attempt, and all addresses in the white list are added.
The following flow chart is intended to provide a logical
sequence of steps while attempting to diagnose the problem
where a guest application is unable to send and/or receive
packets using one or more SR-IOV devices. In geneeral,
process boxes with a orange exiting arrow imply a question of
problem still exists along that path; if the answer is _No,
_ then following through the chart ceases at that point, and
continues when the answer is Yes. Process boxes which have
an exiting black arrow indicate an unconditional flow into
the next element. 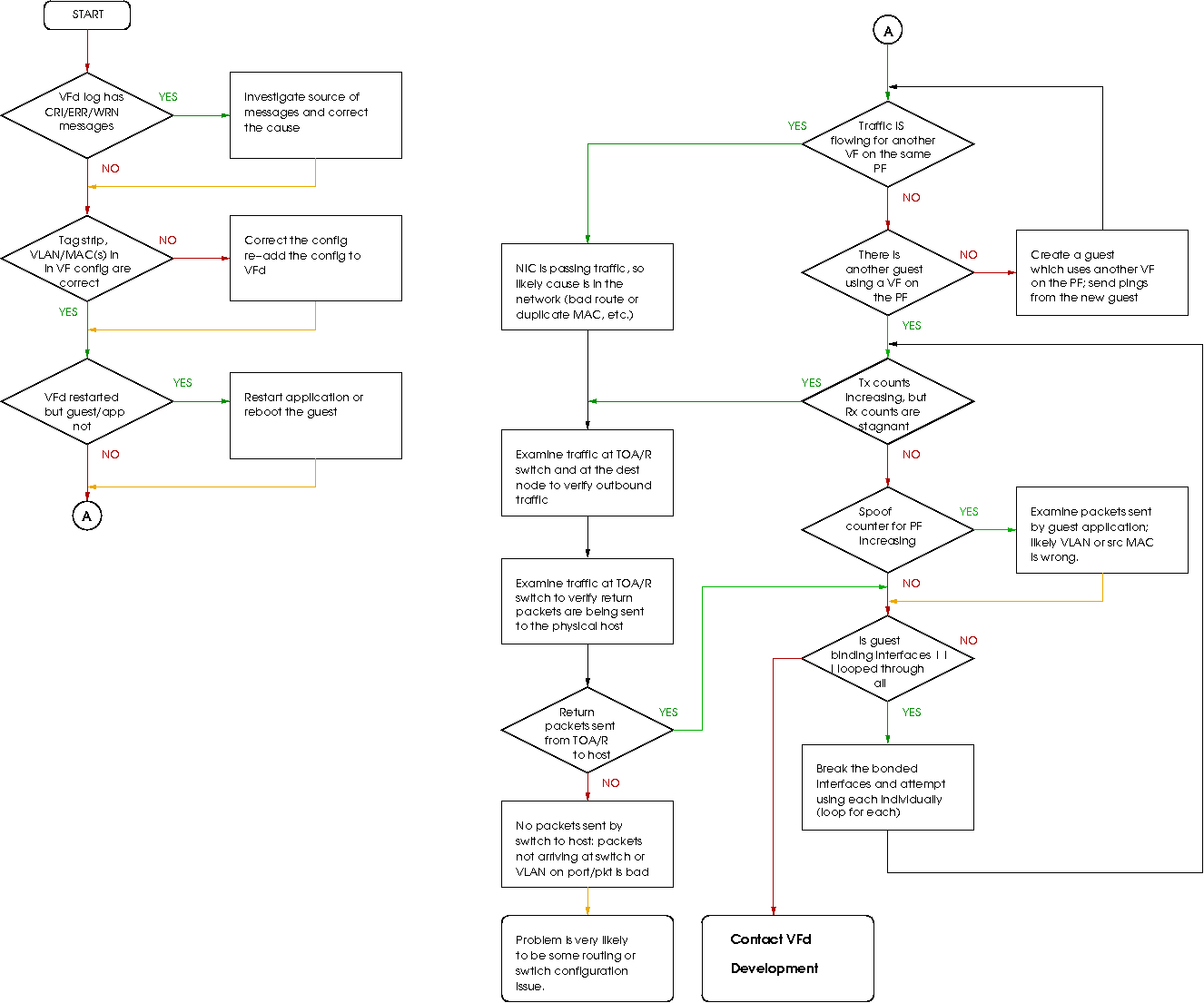
Figure 10: Basic diagnostic flow chart.
Title: VFd Diagnosis Guide
File: ops_trouble.xfm
Original: 6 August 2018
Revised: 10 August 2018
Formatter: tfm V2.2/0a266