Column Store
contribute by wy1433
BaikalStore默认采用行式存储,cstore为BaikalStore的engine模块提供了列存特性,CREATE TABLE时可以设置 ENGINE=Rocksdb_cstore 开启。
目前,用户需要根据不同的业务场景选择适当的存储方式,一般分类如下:
- Row format for OLTP(Online Transactional Processing, 联机事务处理):be good at point/short access
- Column format for OLAP(Online Analytical Processing, 联机分析处理):be good at Large/batch process
未来,行存与列存节点可以做到在Raft-Group层面共存,由DB根据SQL执行代价模型自动选择rstore/cstore, 实现HTAP(Hybrid Transaction and Analytical Process,混合事务和分析处理),这块的设计实现,可以参考TiDB + TiFlash : 朝着真 HTAP 平台演进。而cstore在实现过程中也保留着与rstore高度的兼容性,非常适合未来的混存方案。
- Column Storage stores data in columns instead of rows
- Suitable for analytical workload : Possible for column pruning👍
- Compression made possible and further IO reduction : 1/5 on average storage requirement👍
- Bad small random read and write : Which is the typical workload for OLTP👎
- Rowstore is the classic format for databases
- Researched and optimized for OLTP scenario for decades:+1:
- Cumbersome in analytical use cases:-1:
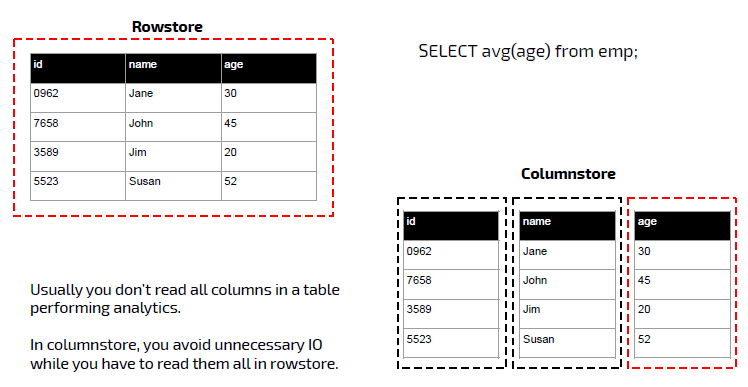
# 统计每个广告平台的记录数量
SELECT CounterID, count() FROM hits GROUP BY CounterID ORDER BY count() DESC LIMIT 20
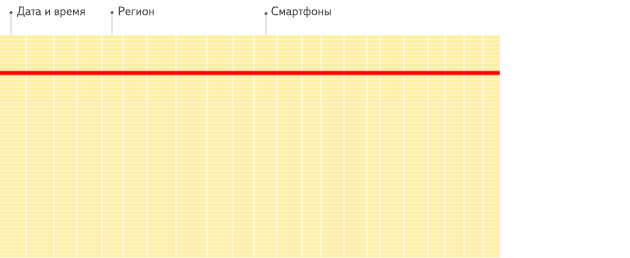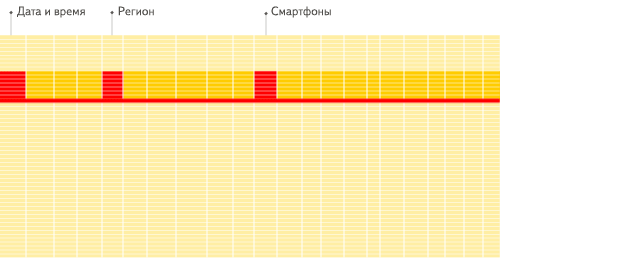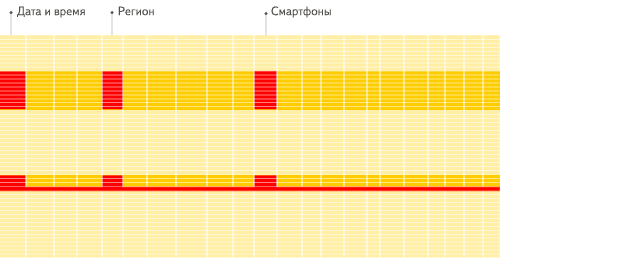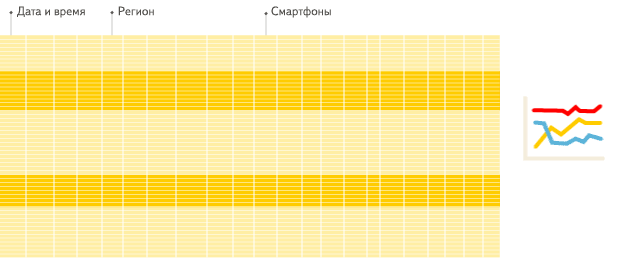
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
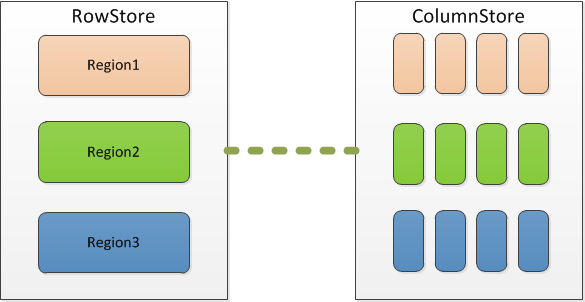
在BakalDB中Region是存储与调度的基本单位,同一区间[start_key, end_key)内所有数据(主键聚簇索引,非主键二级索引),均位于同一Region下,参考: 索引的选择。其中:
- primary:主键聚簇索引,可以看为按主键key(primary key)排序value行存的key-value对
- secondaries:非主键索引,可以看为按索引key(second key) 排序value为一级索引指针的key-value对
通过以上分析可以看出,primary是行存的,secondary可以看成关于索引列的列存结构,因为同一索引在rocksdb里是连续存放的,因此我们改造重点在于primary如何让同一column的数据在kv里连续存放。cstore是通过把primary拆分为 primary + primary_columns来实现的。
同时cstore在key的编码格式上保持了与row-store完全兼容,同样采用(region_id + index_id + pure_key)原有编码格式, 其中primary, secondaries完全一致, 新增的primary_columns部分index_id进行了特殊处理,使其能同时表达IndexID+ColumnID的含义。
primary
Key format: region_id(8 bytes) + table_id(8 bytes) + primary_key_fields;
Value format: protobuf of all non-primary key fields;
primary
Key format: region_id(8 bytes) + table_id(8 bytes) + primary_key_fields;
Value format: null;
primary_columns
Key format: region_id(8 bytes) + table_id(4 bytes) + field_id(4 bytes) + primary_key_fields;
Value format: one of non-primary key fields encode value;
- 修改primary: value 由record 变为null
- 新增primary_column:用于存储某非主键列,因其编码前缀相同,所以其在rocksdb中一定是连续存放的
- key:table_id部分由append_i64(table_id) 改为 append_i32(table_id).append_i32(column_id)。表id取值范围由LONG_MAX变为INT_MAX(2147483647),已足够用。
- value:column value
The commands below create a table and insert some data. An annotated KV dump follows.
CREATE TABLE `TestDB`.`region` (
`R_REGIONKEY` INTEGER NOT NULL,
`R_NAME` CHAR(25) NOT NULL,
`R_COMMENT` VARCHAR(152),
PRIMARY KEY (`R_REGIONKEY`));
INSERT INTO region VALUES
(0,'AFRICA','lar deposits.'),
(1,'AMERICA','hs use ironic'),
(2,'ASIA','ges. thinly'),
(3,'EUROPE','ly final'),
(4,'MIDDLE EAST','uickly special');
Here is the relevant debug log:
key=8000000000000006800000068000000280000000,val=AFRICA,res=OK
key=8000000000000006800000068000000380000000,val=lar deposits.,res=OK
key=8000000000000006800000068000000280000001,val=AMERICA,res=OK
key=8000000000000006800000068000000380000001,val=hs use ironic,res=OK
key=8000000000000006800000068000000280000002,val=ASIA,res=OK
key=8000000000000006800000068000000380000002,val=ges. thinly,res=OK
key=8000000000000006800000068000000280000003,val=EUROPE,res=OK
key=8000000000000006800000068000000380000003,val=ly final,res=OK
key=8000000000000006800000068000000280000004,val=MIDDLE EAST,res=OK
key=8000000000000006800000068000000380000004,val=uickly special,res=OK
Here is the first log with annotations:
/8000000000000006/80000006/80000002/80000000 : AFRICA
^--------------- ^------- ^------- ^------- ^-----
| | | | |
Region ID (6) | | | Value encoding (AFRICA)
| | |
Table ID (6) |
| |
Column ID (2)
|
Primary key (0)
int put_primary_columns(const TableKey& primary_key, SmartRecord record);
int get_update_primary_columns(
const TableKey& primary_key,
SmartRecord val,
std::vector<int32_t>& fields);
int remove_columns(const TableKey& primary_key);
int get_next_columns(SmartRecord record);
Filter
write_local_rocksdb_for_split