[SYCL][Graph] Node Profiling #353
Closed
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
EwanC
reviewed
Jan 25, 2024
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
EwanC
reviewed
Jan 26, 2024
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
EwanC
approved these changes
Jan 29, 2024
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
Bensuo
reviewed
Jan 29, 2024
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
sycl/doc/extensions/experimental/sycl_ext_oneapi_graph.asciidoc
Outdated
Show resolved
Hide resolved
…77231) This patch tries to simplify `X | Y` by replacing occurrences of `Y` in `X` with 0. Similarly, it tries to simplify `X & Y` by replacing occurrences of `Y` in `X` with -1. Alive2: https://alive2.llvm.org/ce/z/cNjDTR Note: As the current implementation is too conservative in the one-use checks, I cannot remove other existing hard-coded simplifications if they involves more than two instructions (e.g, `A & ~(A ^ B) --> A & B`). Compile-time impact: http://llvm-compile-time-tracker.com/compare.php?from=a085402ef54379758e6c996dbaedfcb92ad222b5&to=9d655c6685865ffce0ad336fed81228f3071bd03&stat=instructions%3Au |stage1-O3|stage1-ReleaseThinLTO|stage1-ReleaseLTO-g|stage1-O0-g|stage2-O3|stage2-O0-g|stage2-clang| |--|--|--|--|--|--|--| |+0.01%|-0.00%|+0.00%|-0.02%|+0.01%|+0.02%|-0.01%| Fixes #76554.
Some time ago, I did a similar patch for local variables. Initializing global variables can fail as well: ```c++ constexpr int a = 1/0; static_assert(a == 0); ``` ... would succeed in the new interpreter, because we never saved the fact that `a` has not been successfully initialized.
After this change, all current compiler-rt:* labels on GitHub are covered.
* Print `ReturnLoc`, `ReturnVal`, and `ThisPointeeLoc` if applicable. * For entries in `LocToVal` that correspond to declarations, print the names of the declarations next to them. I've removed the FIXME because all relevant fields are now being dumped. I'm not sure we actually need the capability for the caller to specify which fields to dump, so I've simply deleted this part of the comment. Some examples of the output:  
Make the wmma intrinsic type signatures to be canonical. We need a type signature as long as the type is not fixed. However, when an argument's type matches a previous argument's type, we do not need the signature for this argument. This patch fixes three general cases: 1. add missing signatures 2. remove signatures for matching arguments 3. reorer the signatures -- return type signature should always appear first
…0108) This re-applies 30155fc with a fix for clangd. ### Description clang don't evaluate the object argument of `static operator()` and `static operator[]` currently, for example: ```cpp #include <iostream> struct Foo { static int operator()(int x, int y) { std::cout << "Foo::operator()" << std::endl; return x + y; } static int operator[](int x, int y) { std::cout << "Foo::operator[]" << std::endl; return x + y; } }; Foo getFoo() { std::cout << "getFoo()" << std::endl; return {}; } int main() { std::cout << getFoo()(1, 2) << std::endl; std::cout << getFoo()[1, 2] << std::endl; } ``` `getFoo()` is expected to be called, but clang don't call it currently (17.0.6). This PR fixes this issue. Fixes #67976, reland #68485. ### Walkthrough - **clang/lib/Sema/SemaOverload.cpp** - **`Sema::CreateOverloadedArraySubscriptExpr` & `Sema::BuildCallToObjectOfClassType`** Previously clang generate `CallExpr` for static operators, ignoring the object argument. In this PR `CXXOperatorCallExpr` is generated for static operators instead, with the object argument as the first argument. - **`TryObjectArgumentInitialization`** `const` / `volatile` objects are allowed for static methods, so that we can call static operators on them. - **clang/lib/CodeGen/CGExpr.cpp** - **`CodeGenFunction::EmitCall`** CodeGen changes for `CXXOperatorCallExpr` with static operators: emit and ignore the object argument first, then emit the operator call. - **clang/lib/AST/ExprConstant.cpp** - **`ExprEvaluatorBase::handleCallExpr`** Evaluation of static operators in constexpr also need some small changes to work, so that the arguments won't be out of position. - **clang/lib/Sema/SemaChecking.cpp** - **`Sema::CheckFunctionCall`** Code for argument checking also need to be modify, or it will fail the test `clang/test/SemaCXX/overloaded-operator-decl.cpp`. - **clang-tools-extra/clangd/InlayHints.cpp** - **`InlayHintVisitor::VisitCallExpr`** Now that the `CXXOperatorCallExpr` for static operators also have object argument, we should also take care of this situation in clangd. ### Tests - **Added:** - **clang/test/AST/ast-dump-static-operators.cpp** Verify the AST generated for static operators. - **clang/test/SemaCXX/cxx2b-static-operator.cpp** Static operators should be able to be called on const / volatile objects. - **Modified:** - **clang/test/CodeGenCXX/cxx2b-static-call-operator.cpp** - **clang/test/CodeGenCXX/cxx2b-static-subscript-operator.cpp** Matching the new CodeGen. ### Documentation - **clang/docs/ReleaseNotes.rst** Update release notes. --------- Co-authored-by: Shafik Yaghmour <shafik@users.noreply.github.com> Co-authored-by: cor3ntin <corentinjabot@gmail.com> Co-authored-by: Aaron Ballman <aaron@aaronballman.com>
…79999) Here's an example of the output: 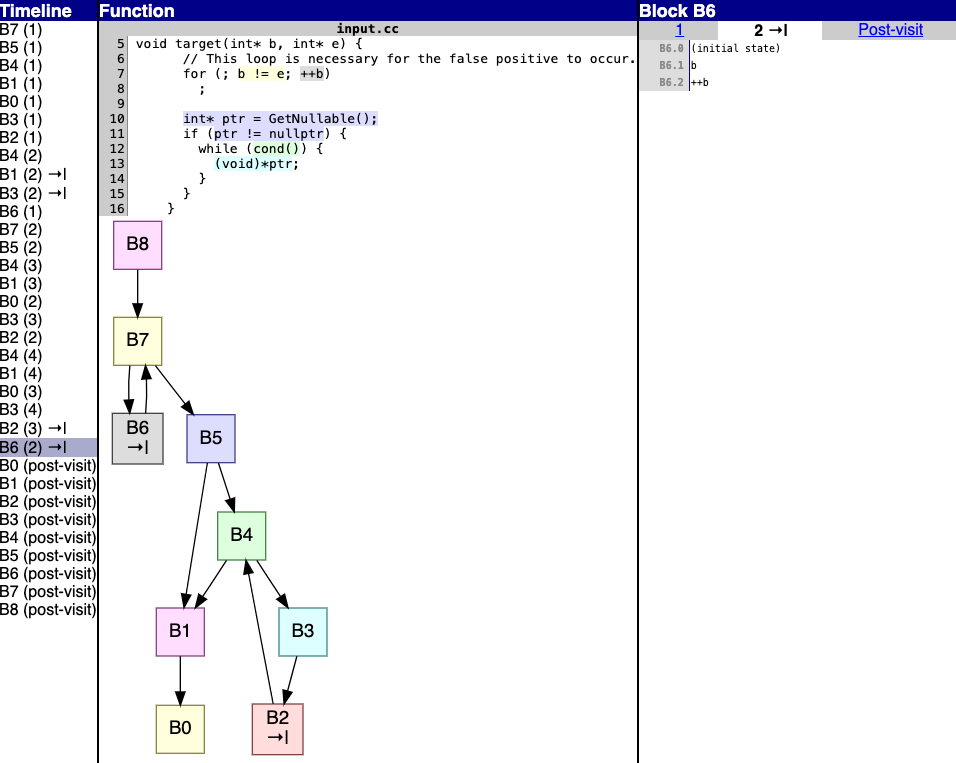
This patch replaces the template trick with a constexpr function that is more readable. Once C++20 is available in our code base, we can remove the constexpr function in favor of std::bit_ceil.
Enable, test, and document the support for fusing rounded range kernels. This mostly worked already – we just have to query the original kernel's global size, and use that to compute the private memory size used for internalization. --------- Signed-off-by: Julian Oppermann <julian.oppermann@codeplay.com>
This patch folds: ``` ((bitcast X to int) <s 0 ? -X : X) -> fabs(X) ((bitcast X to int) >s -1 ? X : -X) -> fabs(X) ((bitcast X to int) <s 0 ? X : -X) -> -fabs(X) ((bitcast X to int) >s -1 ? -X : X) -> -fabs(X) ``` Alive2: https://alive2.llvm.org/ce/z/rGepow
Updates the commit tag for the OCK.
…ts (intel#12529) This will make the two tests run in the presence of either CPU OR GPU and not requiring both to be present to run.
See llvm/llvm-project#79261 for details. It shows that clang-repl uses a different target triple with clang so that it may be problematic if the calng-repl reads the generated BMI from clang in a different target triple. While the underlying issue is not easy to fix, this patch tries to make this test green to not bother developers.
…l#12524) Show detailed error messages when users try to fuse kernels with incompatible ND-ranges, showing different errors for each different scenario. Also combine the validation and fusion logic to reduce the number of ND-ranges list traversals. --------- Signed-off-by: Victor Perez <victor.perez@codeplay.com>
…80079)
Similar to #78403, but for scalable `vwadd(u).wv`, given that #76785 is recommited.
### Code
```
define <vscale x 8 x i64> @vwadd_wv_mask_v8i32(<vscale x 8 x i32> %x, <vscale x 8 x i64> %y) {
%mask = icmp slt <vscale x 8 x i32> %x, shufflevector (<vscale x 8 x i32> insertelement (<vscale x 8 x i32> poison, i32 42, i64 0), <vscale x 8 x i32> poison, <vscale x 8 x i32> zeroinitializer)
%a = select <vscale x 8 x i1> %mask, <vscale x 8 x i32> %x, <vscale x 8 x i32> zeroinitializer
%sa = sext <vscale x 8 x i32> %a to <vscale x 8 x i64>
%ret = add <vscale x 8 x i64> %sa, %y
ret <vscale x 8 x i64> %ret
}
```
### Before this patch
[Compiler Explorer](https://godbolt.org/z/xsoa5xPrd)
```
vwadd_wv_mask_v8i32:
li a0, 42
vsetvli a1, zero, e32, m4, ta, ma
vmslt.vx v0, v8, a0
vmv.v.i v12, 0
vmerge.vvm v24, v12, v8, v0
vwadd.wv v8, v16, v24
ret
```
### After this patch
```
vwadd_wv_mask_v8i32:
li a0, 42
vsetvli a1, zero, e32, m4, ta, ma
vmslt.vx v0, v8, a0
vsetvli zero, zero, e32, m4, tu, mu
vwadd.wv v16, v16, v8, v0.t
vmv8r.v v8, v16
ret
```
The `memref.subview` verifier currently checks result shape, element type, memory space and offset of the result type. However, the strides of the result type are currently not verified. This commit adds verification of result strides for non-rank reducing ops and fixes invalid IR in test cases. Verification of result strides for ops with rank reductions is more complex (and there could be multiple possible result types). That is left for a separate commit. Also refactor the implementation a bit: * If `computeMemRefRankReductionMask` could not compute the dropped dimensions, there must be something wrong with the op. Return `FailureOr` instead of `std::optional`. * `isRankReducedMemRefType` did much more than just checking whether the op has rank reductions or not. Inline the implementation into the verifier and add better comments. * `produceSubViewErrorMsg` does not have to be templatized.
…ocOrder (#80015) Previously we called ignoreCSRForAllocationOrder on every alias of every CSR which was expensive on targets like AMDGPU which define a very large number of overlapping register tuples. On such targets it is simpler and faster to call ignoreCSRForAllocationOrder once for every physical register. Differential Revision: https://reviews.llvm.org/D146735
…2521) oneapi-src/unified-runtime#1070 and intel#11952 introduced a new variant of the `enableCUDATracing` function that takes a context pointer parameter, replacing the parameterless variant of that function. The older variant will be removed from UR once this PR is merged.
Improved joint_matrix layout test coverage. The test framework that the cuda backend tests use has been updated to support all possible `joint_matrix` gemm API combinations, including all matrix layouts. the gemm header is backend agnostic; hence all backends could use this test framework in the future. This test framework can also act as an example to show how to deal with different layout combinations when computing a general GEMM. Signed-off-by: JackAKirk <jack.kirk@codeplay.com>
Split out from #78417. Reviewers: topperc, asb, kito-cheng Reviewed By: asb Pull Request: llvm/llvm-project#79248
Add support for load/store operations for a cooperative matrix such that original matrix shape is known and implementations are able to reason about how to deal with the out of bounds. CapabilityCooperativeMatrixCheckedInstructionsINTEL = 6192 CooperativeMatrixLoadCheckedINTEL = 6193 CooperativeMatrixStoreCheckedINTEL = 6194 Original commit: KhronosGroup/SPIRV-LLVM-Translator@b62cb55
The goal of the PR is to add API to SPIR-V LLVM Translator to query error message by an error code as discussed in intel#2298 A need and possible application is a way to generate human-readable error info by error codes returned by other SPIRV Translator API calls, including getSpirvReport(). Original commit: KhronosGroup/SPIRV-LLVM-Translator@afe1971
Map @llvm.frexp intrinsic to OpenCL Extended Instruction frexp builtin.
The difference in signatures and return values is covered by extracting/combining values from and into composite type.
LLVM IR:
{ float %fract, i32 %exp } @llvm.frexp.f32.i32(float %val)
SPIR-V:
{ float %fract } ExtInst frexp (float %val, i32 %exp)
Original commit:
KhronosGroup/SPIRV-LLVM-Translator@e8b2018
…ntel#2288) The translator failed assertion with V->user_empty() during regularize function when shl i1 or lshr i1 result is used. E.g. %2 = shl i1 %0 %1 store %2, ptr addrspace(1) @G.1, align 1 Instruction shl i1 is converted to lshr i32 which arithmetic have the same behavior. Original commit: KhronosGroup/SPIRV-LLVM-Translator@239fbd4
…#2331) Add support for checked matrix construct instruction. Specification draft: https://github.com/intel/llvm/blob/2fa153ee852ea3d7d64df097f1f494cddacee90e/sycl/doc/design/spirv-extensions/SPV_INTEL_joint_matrix.asciidoc Original commit: KhronosGroup/SPIRV-LLVM-Translator@a1b1f49
Replace some deprecated 'startswith' and 'endswith' with 'starts_with' and 'ends_with' to clear some warnings when building SYCL compiler. --------- Signed-off-by: jinge90 <ge.jin@intel.com>
We currently support -O3 for Linux compilations, expand this to also be available on Windows. This also better aligns with our existing product offerings.
The compiler was crashing when the user requested fp-accuracy for the functions in a call of the form f1(f2(f3 ...), where f1, f2 and f3 were fpbuiltin but the innermost function didn't have an fpbuiltin. The current builtinID was used instead of getting the builtinID from the current function. that created a crash in the compiler. This patch fixes the issue and renames the function EmitFPBuiltinIndirectCall to MaybeEmitFPBuiltinofFD .
intel#12297) We want to change the signature of `piMemGetNativeHandle` for reasons explained here oneapi-src/unified-runtime#1199 Corresponding UR PR: oneapi-src/unified-runtime#1226 A previous PR added a new entry point intel#12199 but it was decided that it is better to modify the existing entry point
…:intel::math (intel#12571) Signed-off-by: jinge90 <ge.jin@intel.com>
LLVM: llvm/llvm-project@178719e SPIRV-LLVM-Translator: KhronosGroup/SPIRV-LLVM-Translator@a1b1f49
Problems found by Gregory (thanks!): 1) There were some duplicated tests, remove those 2) We didn't test non-LSC mask on Gen12 3) We get an ambiguous call because we had an old function that didn't have VS, but the new functions have default VS=1, so we don't need the old one. 4) When we pass a simd_view for the vals, we got a template match failure. This is the same issue we hit in the compile-time tests where even if we have a simd_view overload the compiler can't infer N, so we need to provide T,N anyway, so add that in the tests. I tested this on Gen12. Signed-off-by: Sarnie, Nick <nick.sarnie@intel.com>
…12579) Adding `EXCLUDE_FROM_ALL` to the `add_subdirectory` for the OneAPI Construction Kit, in order to to avoid building its components unless they are required by the SYCL toolchain.
The FPGA emulator is currently affected by the same issue as the CPU runtime. Signed-off-by: John Pennycook <john.pennycook@intel.com>
…ntel#12548) We have flakyness in nightly testing results. Having more variety would helpfully provide some insights on conditions when it happens. The task is only executed once a day, so extra resources needed shouldn't affect the load on the runners much.
|
Upstream PR intel#12592 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
This PR:
ext_oneapi_get_profiling_info(ext::node Node).