

- ZEB: Zero-shot Evaluation Benchmark
- Video Preprocess Code
- 3D Reconstruction
- Inference code
- gim_roma
- gim_dkm
- gim_loftr
- gim_lightglue
- Training code
We are actively continuing with the remaining open-source work and appreciate everyone's attention.
Go to Huggingface to quickly try our model online.
I set up the running environment on a new machine using the commands listed below.
[ Click to show commands ]
conda create -n gim python=3.9
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch -c conda-forge
conda install xformers -c xformers
pip install albumentations==1.0.1 --no-binary=imgaug,albumentations
pip install colour-demosaicing==0.2.2
pip install pytorch-lightning==1.5.10
pip install opencv-python==4.5.3.56
pip install imagesize==1.2.0
pip install kornia==0.6.10
pip install einops==0.3.0
pip install loguru==0.5.3
pip install joblib==1.0.1
pip install yacs==0.1.8
pip install h5py==3.1.0
pip install matplotlib
pip install omegaconf
pip install triton- Clone the repository
git clone https://github.com/xuelunshen/gim.git
cd gim-
Download
gim_dkmmodel weight from Google Drive or OneDrive -
Put it on the folder
weights -
Run the following commands
[ Click to show commands ]
python demo.py --model gim_dkm
# or
python demo.py --model gim_loftr
# or
python demo.py --model gim_lightglue- The code will match
a1.pnganda2.pngin the folderassets/demo,
and outputa1_a2_match.pnganda1_a2_warp.png.
[ Click to show
a1.png
and
a2.png ]


[ Click to show
a1_a2_match.png ]

a1_a2_match.png is a visualization of the match between the two images
[ Click to show
a1_a2_warp.png ]

a1_a2_warp.png shows the effect of projecting image a2 onto image a1 using homography
[ Click to show other images ]






Because of some reasons, we cannot provide specific YouTube videos used for training, but I can tell you that using the keywords
walk inorwalk throughto search on YouTube will find relevant videos. The videos used for processing need to be shot without any processing. There should be no editing, no transitions, no special effects, etc. Below, I will introduce the entire process.
- Put the id of the YouTube video you want to process into the
video_list.txtfile. For example, the id of the videohttps://www.youtube.com/watch?v=Od-rKbC30TMisOd-rKbC30TM. Now thevideo_list.txtfile already contains this example video. You can do nothing now and directly go to the second step. - Use the command
chmod +x process_videos.shto give theprocess_videos.shfile execution permission - Use the command
./process_videos.sh video_list.txtto run the video processing code - Use the command
python -m datasets.walk.propagate video_list.txtto run the matching label propagation code - Use the command
python -m datasets.walk.walk video_list.txtto run the visualization code
The processing results and intermediate files are located in the
data/ZeroMatchfolder, and the visualization results are in thedump/walkfolder. If everything goes well, you should see a result similar to the image below (click to expand the image).
[ Click to show visualization results ]

[ ⚠️ If you encounter VideoReader errors from torchvision, click to expand ]
Create a new conda environment and install the dependencies below, then run the video processing code.
conda create -n gim-video python=3.8.10
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
pip install albumentations==1.0.1 --no-binary=imgaug,albumentations
pip install pytorch-lightning==1.5.10
pip install opencv-python==4.5.3.56
pip install imagesize==1.2.0
pip install kornia==0.6.10
pip install einops==0.3.0
pip install loguru==0.5.3
pip install joblib==1.0.1
pip install yacs==0.1.8
pip install h5py==3.1.0After processing the video, it's time to train the network. The training code for
gim-loftris in thetrain-gim-loftrbranch of the repository. The training code forgim-dkmandgim-lightgluewill be released later. However, adapting the video data bygimto the architecture ofdkmandlightglueis actually simpler than adapting it toloftr. Therefore, we first release the training code forgim-loftr.
- Use the command
git checkout train-gim-loftrto switch to thetrain-gim-loftrbranch - Use the command below to run the training code
#! /bin/bash
GPUS=8
NNODES=5
GITID=$(git rev-parse --short=8 HEAD)
MODELID=$(cat /dev/urandom | tr -dc 'a-z0-9' | fold -w 8 | head -n 1)
python -m torch.distributed.launch --nproc_per_node=gpu --nnodes=$WORLD_SIZE --node_rank $RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT --use_env train.py --num_nodes $NNODES --gpus $GPUS --max_epochs 10 --maxlen 938240 938240 938240 --lr 0.001 --min_lr 0.00005 --git $GITID --wid $MODELID --resample --img_size 840 --batch_size 1 --valid_batch_size 2We train gim-loftr on 5 A100 nodes, with each node having 8 GPUs with 80 GB memory. The parameters WORLD_SIZE, RANK, MASTER_ADDR, MASTER_PORT are for distributed training and should be automatically obtained from the cluster environment. If you are using single machine with single GPU or multiple GPUs, you can run the training code with the command below.
python train.py --num_nodes 1 --gpus $GPUS --max_epochs 10 --maxlen 938240 938240 938240 --lr 0.001 --min_lr 0.00005 --git $GITID --wid $MODELID --resample --img_size 840 --batch_size 1 --valid_batch_size 2The code for 3D reconstruction in this repository is implemented based on hloc.
First, install colmap and pycolmap according to hloc's README.
Then, download the semantic-segmentation's model parameters from Google Drive or OneDrive and put the model parameters in the folder weights.
Next, create some folders. If you want to reconstruct a room in 3D, run the following command:
mkdir -p inputs/room/imagesThen, put images of the room to be reconstructed in 3D into the images folder.
Finally, run the following command to perform a 3D reconstruction:
sh reconstruction.sh room gim_dkm
# or
sh reconstruction.sh room gim_lightglueTips:
At present, the code for 3D reconstruction defaults to pairing all images pairwise, and then performing image matching and reconstruction,
For better reconstruction results, it is recommended to modify the code according to the actual situation and adjust the paired images.
- Create a folder named
zeb. - Download zip archives containing the ZEB data from the URL, put it into the
zebfolder and unzip zip archives. - Run the following commands
[ Click to show commands ]
The number 1 below represents the number of GPUs you want to use. If you want to use 2 GPUs, change the number 1 to 2.
sh TEST_GIM_DKM.sh 1
# or
sh TEST_GIM_LOFTR.sh 1
# or
sh TEST_GIM_LIGHTGLUE.sh 1
# or
sh TEST_ROOT_SIFT.sh 1- Run the command
python check.pyto check if everything outputs"Good". - Run the command
python analysis.py --dir dump/zeb --wid gim_dkm --version 100h --verboseto get result. - Paste the ZEB result to the Excel file named
zeb.xlsx.
[ Click to show 📊 ZEB Result ]
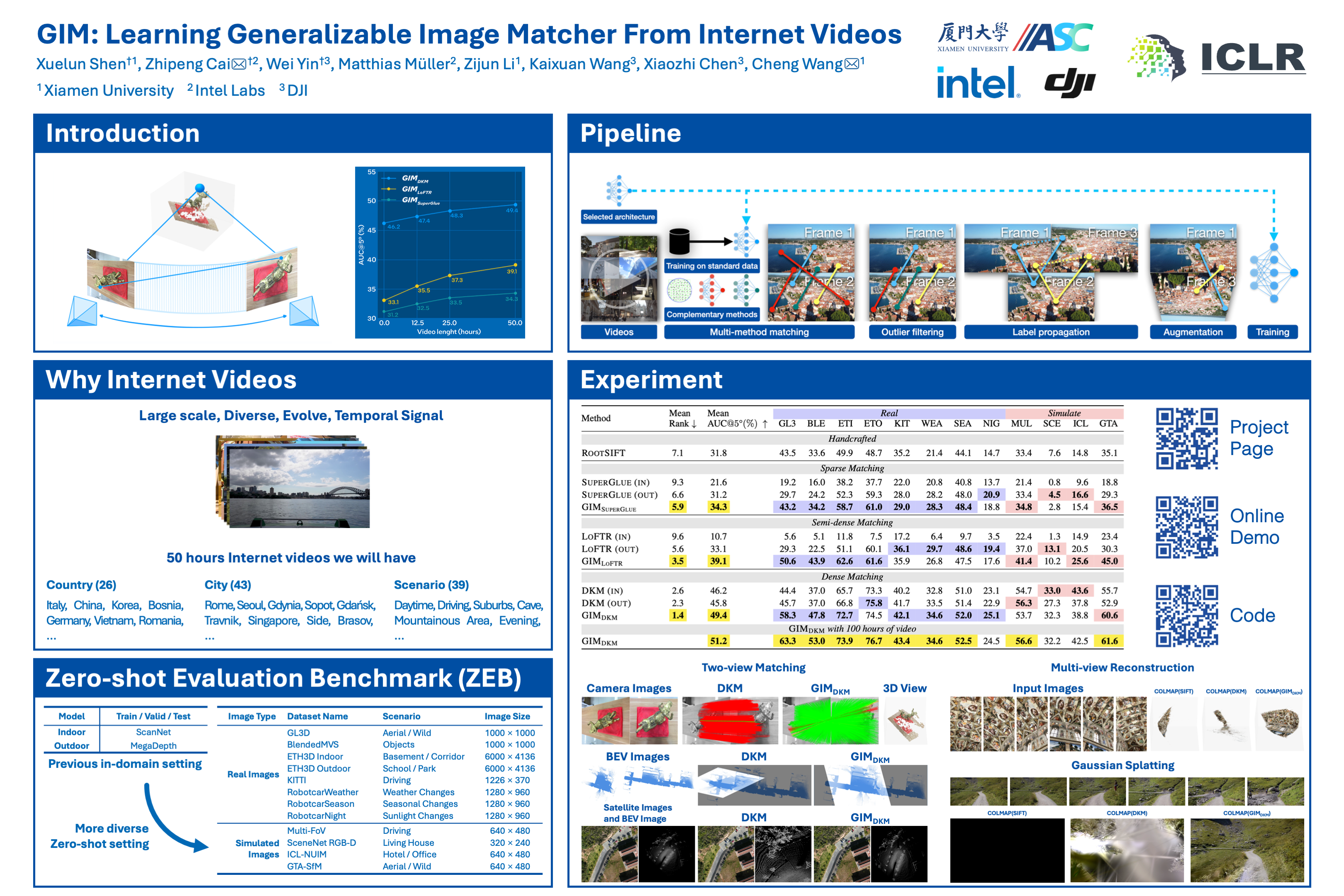
The data in this table comes from the ZEB: Zero-shot Evaluation Benchmark for Image Matching proposed in the paper. This benchmark consists of 12 public datasets that cover a variety of scenes, weather conditions, and camera models, corresponding to the 12 test sequences starting from GL3 in the table.
Method |
Mean AUC@5° (%) ↑ |
GL3 | BLE | ETI | ETO | KIT | WEA | SEA | NIG | MUL | SCE | ICL | GTA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Handcrafted | ||||||||||||||
| RootSIFT | 31.8 | 43.5 | 33.6 | 49.9 | 48.7 | 35.2 | 21.4 | 44.1 | 14.7 | 33.4 | 7.6 | 14.8 | 35.1 | |
| Sparse Matching | ||||||||||||||
| SuperGlue (in) | 21.6 | 19.2 | 16.0 | 38.2 | 37.7 | 22.0 | 20.8 | 40.8 | 13.7 | 21.4 | 0.8 | 9.6 | 18.8 | |
| SuperGlue (out) | 31.2 | 29.7 | 24.2 | 52.3 | 59.3 | 28.0 | 28.4 | 48.0 | 20.9 | 33.4 | 4.5 | 16.6 | 29.3 | |
| GIM_SuperGlue (50h) |
34.3 | 43.2 | 34.2 | 58.7 | 61.0 | 29.0 | 28.3 | 48.4 | 18.8 | 34.8 | 2.8 | 15.4 | 36.5 | |
| LightGlue | 31.7 | 28.9 | 23.9 | 51.6 | 56.3 | 32.1 | 29.5 | 48.9 | 22.2 | 37.4 | 3.0 | 16.2 | 30.4 | |
| ✅ | GIM_LightGlue (100h) |
38.3 | 46.6 | 38.1 | 61.7 | 62.9 | 34.9 | 31.2 | 50.6 | 22.6 | 41.8 | 6.9 | 19.0 | 43.4 |
| Semi-dense Matching | ||||||||||||||
| LoFTR (in) | 10.7 | 5.6 | 5.1 | 11.8 | 7.5 | 17.2 | 6.4 | 9.7 | 3.5 | 22.4 | 1.3 | 14.9 | 23.4 | |
| LoFTR (out) | 33.1 | 29.3 | 22.5 | 51.1 | 60.1 | 36.1 | 29.7 | 48.6 | 19.4 | 37.0 | 13.1 | 20.5 | 30.3 | |
| ✅ | GIM_LoFTR (50h) |
39.1 | 50.6 | 43.9 | 62.6 | 61.6 | 35.9 | 26.8 | 47.5 | 17.6 | 41.4 | 10.2 | 25.6 | 45.0 |
| GIM_LoFTR (100h) |
ToDO | |||||||||||||
| Dense Matching | ||||||||||||||
| DKM (in) | 46.2 | 44.4 | 37.0 | 65.7 | 73.3 | 40.2 | 32.8 | 51.0 | 23.1 | 54.7 | 33.0 | 43.6 | 55.7 | |
| DKM (out) | 45.8 | 45.7 | 37.0 | 66.8 | 75.8 | 41.7 | 33.5 | 51.4 | 22.9 | 56.3 | 27.3 | 37.8 | 52.9 | |
| GIM_DKM (50h) |
49.4 | 58.3 | 47.8 | 72.7 | 74.5 | 42.1 | 34.6 | 52.0 | 25.1 | 53.7 | 32.3 | 38.8 | 60.6 | |
| ✅ | GIM_DKM (100h) |
51.2 | 63.3 | 53.0 | 73.9 | 76.7 | 43.4 | 34.6 | 52.5 | 24.5 | 56.6 | 32.2 | 42.5 | 61.6 |
| RoMa (in) | 46.7 | 46.0 | 39.3 | 68.8 | 77.2 | 36.5 | 31.1 | 50.4 | 20.8 | 57.8 | 33.8 | 41.7 | 57.6 | |
| RoMa (out) | 48.8 | 48.3 | 40.6 | 73.6 | 79.8 | 39.9 | 34.4 | 51.4 | 24.2 | 59.9 | 33.7 | 41.3 | 59.2 | |
| GIM_RoMa | ToDO |
If the paper and code from gim help your research, we kindly ask you to give a citation to our paper ❤️. Additionally, if you appreciate our work and find this repository useful, giving it a star ⭐️ would be a wonderful way to support our work. Thank you very much.
@inproceedings{
xuelun2024gim,
title={GIM: Learning Generalizable Image Matcher From Internet Videos},
author={Xuelun Shen and Zhipeng Cai and Wei Yin and Matthias Müller and Zijun Li and Kaixuan Wang and Xiaozhi Chen and Cheng Wang},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}This repository is under the MIT License. This content/model is provided here for research purposes only. Any use beyond this is your sole responsibility and subject to your securing the necessary rights for your purpose.