Ingest Services
There are a number of different types of ingestion services, but they all serve a similar purpose.
They pull in content (stories, video, audio, blogs, social media) from 3rd parties into this solution.
The general workflow or lifecycle of the ingestion services is to continually scan 3rd parties for new content.
When content is identified a reference is created and a message is pushed to the Kafka event streaming backbone services.
Depending on the type of content that is identified, additional background services are running to perform various actions.
For example there is a Transcription service, and a Natural Language Processing service that can automatically convert audio/video to text, and extract keywords.
Part of the lifecycle requires a generic Content service to identify content that should be sent to Editors.
Content is either pushed or pulled to the solution from 3rd parties. As ingest services run they communicate with the solution database for configuration, settings, schedule. Each service identifies unique content and maintains it's current status. The status represents it's lifecycle as it exists within the Kafka backbone processes (i.e. Transcription, Natural Language Processing, Indexing). As content is imported, if it is binary data like audio/video it will be saved to the appropriate configured data location.
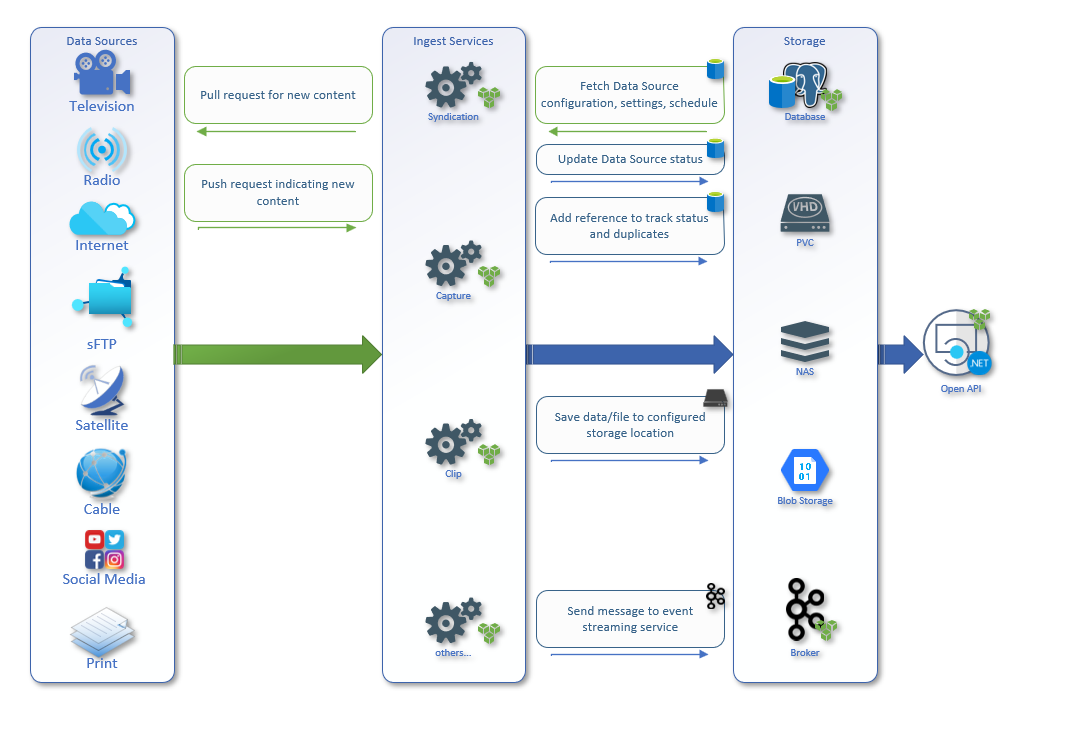
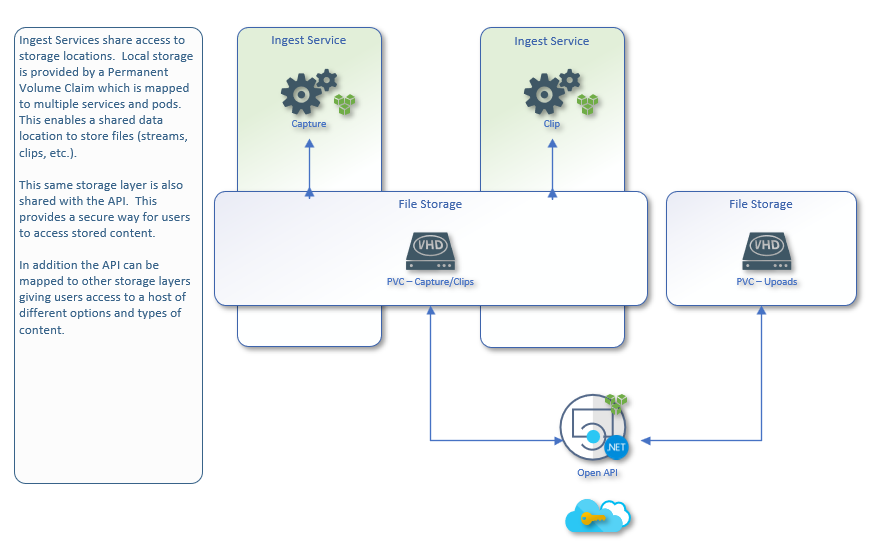
Data locations provide a way to share storage with different services, pods, and components.
A proof of concept for the newspaper ingestion service has been created which helped guide research into the issues presented here. The POC will be referred to occasionally in this discussion.
Newspaper ingestion diverges from the other ingestion services (Syndication, Capture, Clip) in that those data sources are essentially self-published. This means that there is a 1:1 relationship between the data source and a syndication feed (BiV, The Narwal, Castanet etc.) The same goes for a Capture data source, which streams data from a single URL and a Clip data source which extracts clips from a single Capture file.
In contrast, newspapers can have a Many:1 relationship with a publisher. For example, the Blacks News Group publishes content for the following papers and many more:
- Alberni Valley News
- Parksville Qualicum Beach News
- Mission City Record
Publishers will upload many XML files to a specific directory throughout the day. Each file can contain news articles from any number of publications, so maintaining the 1:1 relationship between a publication and a data source would involve some convoluted file parsing. Out of the following news sources:
- The Globe and Mail
- StarMetro
- Blacks News Group
- Meltwater
(these will be referred to as the publishers in this document) only the Globe and Mail and StarMetro are self-published in the sense mentioned above. Jorel handles this situation by recognizing the publisher, rather than the publication, as the data source. I (Stuart) have produced a proof of concept for newspaper ingestion that follows this approach. The main inconsistency between this and the approach taken in the MMIA solution is that there is currently no way to relate a news item to a publication other than through the data source.
The content service currently identifies the publication using the "source" field of the SourceContent model from the Kafka message. This will not currently work for publications that are imported from the Blacks News Group and MeltWater. Adding a "publication" field to the SourceContent model would allow the content service to identify the publication, although this is likely only one of several changes that will be required.
The publishers currently upload content to locations on the TNO production server. I have never had shell access to this server and for the purposes of development relied on example files sent to me by Roberto Correia. In an August 15, 2022 email Roberto proposed this solution to give MMIA timely access to these files:
"I think we want to avoid asking anything of the providers with respect to tweaks or changes to how we receive the content. It’s not as bad as it used to be but it’s still pretty likely that things will get broken on their end if we start asking for changes.
I think the easiest solution would be for me to write a simple cron script on Ragu that checks if there are any new Vancouver Sun imports and copies them to somewhere TNO 2.0 can process. I say easiest but there still could be some hoops to jump through to get Ragu to see where TNO 2.0 exists. The main advantage is that it’s not likely to be disruptive to the current prod environment."
In another email, Roberto described the schedule by which these files are ingested:
"The way it works now the various providers upload their content pretty well whenever although most of it comes in between 10pm -> 6am. Newspaper content at least. Each provider uploads their files to a specific folder and TNO 1.0 monitors those folders. Imports the files as they come in and immediately move them to a processed folder. Once a day that processed folder is cleaned out and those imports are moved into a cold storage location."
This type of schedule is described by MMIA's "continuous" schedule type. Roberto clarified the following in another email:
"As far as TNO 1.0 is concerned it is assuming that any source could come in at any time. So while in practice certain papers come in late evening, others in the morning, some once a week and still other more sporadically TNO doesn’t care. If it shows up it's ingested ASAP."
The removal of these files as candidates for ingestion, by moving them to the "processed" folder, goes a long way toward preventing the re-processing of content, although MMIA's multi-process architecture might complicate this. Ultimately the newspaper service's duplication detection code should prevent the creation of duplicate content.
Three of the four publishers provide content in XML format and these are the only sources that the POC works with at this point (it does not yet import fms files). The Globe and Mail and StarMetro use the News Industry Text Format standard (NITF). This provides some generalized standardization of features, although different approaches are taken to where specific data are stored in the document. For example, the Globe and Mail stores the story id in the "id" attribute of the "pubdata" tag, whereas StarMetro stores it in the "id-string" attribute of the "doc-id" tag. This means that the location from which the newspaper service extracts the id, and other data, needs to be customized for each publisher (this has been done in the POC for the newspaper service).
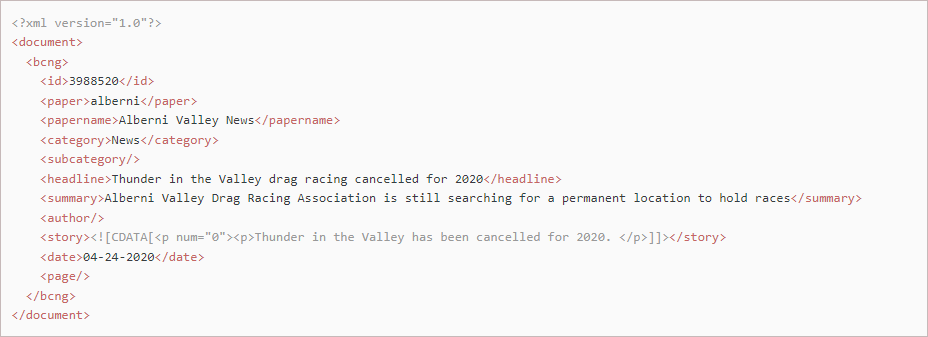
Blacks Newsgroup provides documents with the XML extension, but they do not parse as XML. They are missing a single parent element and have multiple <bcng> elements, at the top level, instead. The POC addresses this by inserting a opening document tag after the XML tag and a closing document tag at the end of the file. The story tags also contain poorly formatted HTML code that breaks the XML parser. The POC avoids this limitation by wrapping the story in CDATA tags.
Meltwater provides content for papers that include:
- The Province
- The Times Colonist
- The Oliver Chronicle
- The Peachland Review
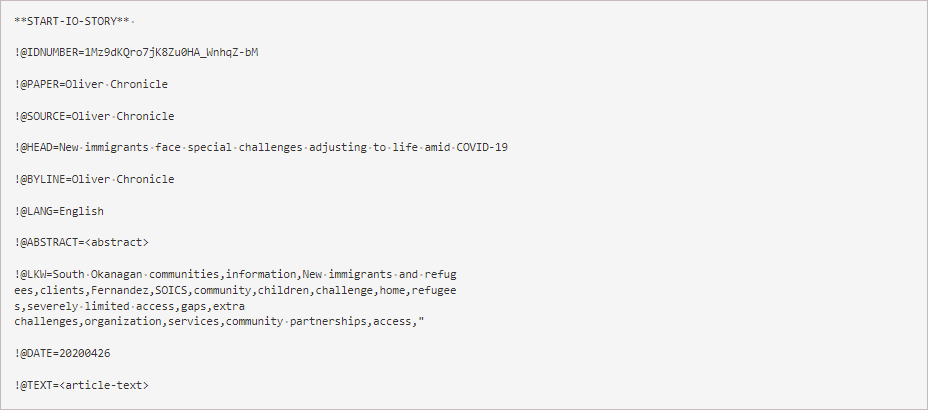
Rather than being an owner of these papers (like the Blacks News Group), MeltWater aggregates content from other publishers. From our perspective, however, we can view them as publishing content that we consume. They send content to us in fms files. Several Google searches have failed to produce any information about this format, but I have included an example article from an fms file below. In contrast with the bcng files, which may each contain items from multiple publications, each MeltWater file contains content from only one publication. The publication from which these articles are sourced is identified using a four character file name prefix (see the list of filenames below for examples). The MeltWater files for the Province and Times Colonist are accompanied by a zip file containing a small low-resolution front page image of the issue that contains the article.
| File Name | Publisher | Article Count | Description |
|---|---|---|---|
| vapr20200426050528.fms | MeltWater | One or more | File containing articles from the Vancouver Province (vapr) published on April 26, 2020 at 5:05:28 am. |
| vitc20200426070528.fms | MeltWater | One or more | File containing articles from the Victoria Times Colonist (vitc) published on April 26, 2020 at 7:05:28 am. |
| vitc20200426070528.zip | MeltWater | One Image | Front page image from the Victoria Times Colonist (vitc) published on April 26, 2020 at 7:05:28 am. |
| bcng-20200426-12.xml | Black's News Group | One or more | Blacks News Group file #12 published on April 26, 2020. |
| news20191220TSG2019122056690490.xml | StarMetro | One | File containing one article from StarMetro published on December 20, 2019 with the unique file id 56690490. |
| 20200427.bcnwbccoronaelder.xml | Globe and Mail | One | File containing one article from the Globe and Mail with the unique article id bcnwbccoronaelder published on April 27, 2020. |
Jira does not display formatted text well, so I grabbed some screenshots of the XML for the three providers. I also included the content of an fms file (Meltwater) although the code to ingest these has not yet been written. The stories in these articles have been trimmed, and some content has been truncated, in order to keep the image dimensions small.
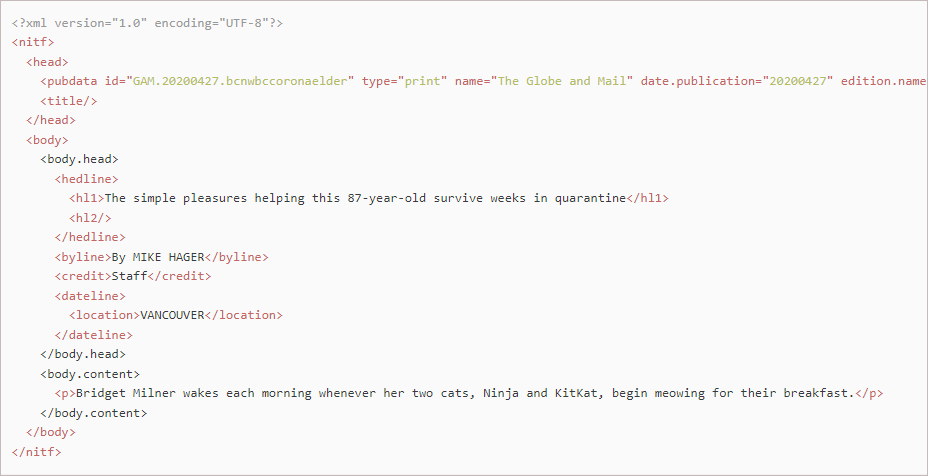
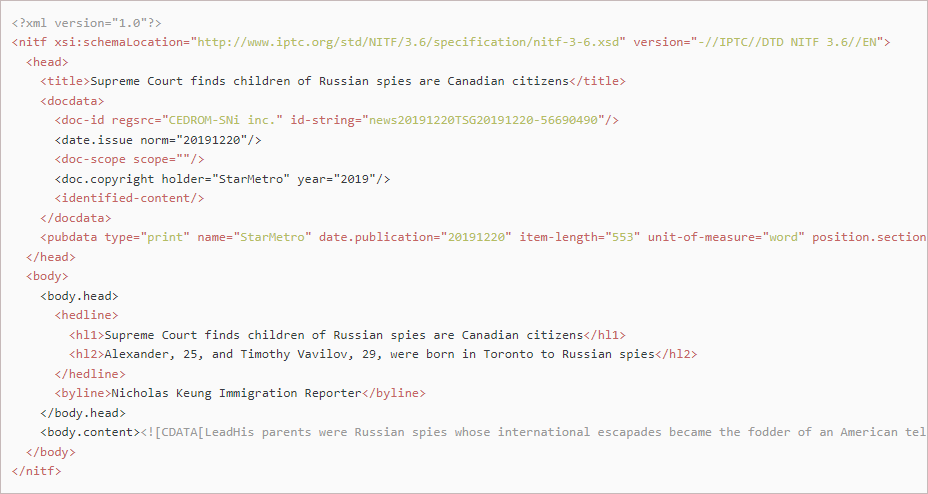
The newspaper service must handle diverse file formats in a standardized fashion. Ultimately news items from all sources must coalesce into the format the service submits to Kafka. This format must also be understood by the content service so it can create news items for the subscriber app to display. The source content format we currently use is shown below:
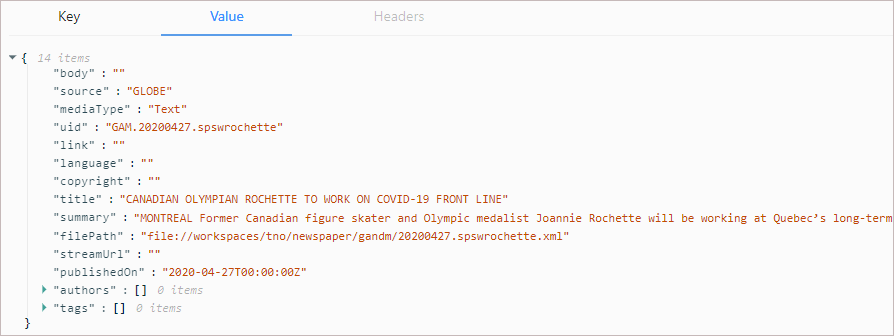
There are several data points that need to be collected for each article in order to make the resulting news item useful:
| Field name | Kafka Equivalent | Notes |
|---|---|---|
| Papername | source | Because Blacks and MeltWater files relate to multiple publications this doesn't currently work for those publications. |
| Headline | title | The title of each article is the link text in the subscriber app. |
| Story | summary | Summaries are only provided for Blacks articles. This is usually used for the story text. |
| Author | authors | Represents the byline of the article. |
| Date | publishedOn | The date the article was published on. No time is provided, but could be extracted from the file name for MeltWater. |
| Id | uid | The value used to index the articles and prevent duplication of content. |
The newspaper service must understand where in the XML document for each data source these fields are stored. I designed a preliminary method for representing this mapping in the Connection string, for each data source, that uses a character delimited text format. The Connection entries for the GLOBE data source are shown below:
"papername": "attr!pubdata!name",
"headline": "hl1",
"story": "body.content",
"author": "byline",
"date": "attr!pubdata!date.publication",
"id": "attr!pubdata!id",
"dateFmt": "yyyyMMdd",
"escape-content": "false",
"add-parent": "false"
The first 6 of these relate to the fields in the table above. The remaining three perform the following functions:
- dateFmt - A format string to use in parsing the date value extracted from the
datefield. - escape-content - Indicates whether the story text should be wrapped in CDATA tags.
- add-parent - Determines whether a top-level parent tag should be added to the document (BCNG only).
These values could be configured in the Ingest Settings tab and written to the Connection string in the same way as for other content types. A mockup of how this might appear is shown below:

In order to provide a flexible newspaper ingestion service, the product owner may require a solution that can parse any import format. The method of extracting data from the file using tag names and attributes, shown above, should allow an administrator or editor to add a new XML newspaper data source without making any code changes. This will not be the case for newspapers that do not provide XML files for ingestion. The FMS file format is a case in point. Obviously, an FMS file will not parse as XML, so it can't be loaded into an XmlDocument object (the approach taken by the POC solution).
Due to this divergence of formats, we could take one of two approaches:
- Keep the code that imports news items in XML format and create a separate method for importing FMS files.
- Build a parser that treats both XML and FMS files as string-delimited file formats, and drop the use of a formal XML parser.
If the FMS file import approach mentioned in point 1 only parses FMS files, we have not met the requirement highlighted above (I'm guessing the PO will want this). If we follow the second approach we may find that the solution is capable of parsing both XML and FMS files and, possibly, other import formats. It is likely that, if approach 2 is followed, it will not handle every unknown file format, so code customizations may be required anyway. Lastly, it's been over 10 years since a new newspaper format was added to TNO, so it may not be cost-effective to provide a one-size-fits-all solution when it may never be used.
Bearing in mind that print publications are waning in importance, as new technologies arise, the ability to dynamically define a newspaper import format may be diminishing in priority. It's also possible that MMIA could negotiate the use of XML in any future agreements with publishers. These are subjects for consideration.
Each publisher has a unique way of formatting story content. It is important that each story is displayed in the subscriber interface in a readable format, but the method by which this is accomplished varies. Currently the POC for the newspaper service saves the XML inner text as the story, which removes all formatting. We'll need to decide whether formatting should be applied prior to sending the text to Kafka, or whether the content service should do this. I have not examined the re-formatting approach taken by Jorel for these story formats yet, but such an examination would guide us in how to reproduce this functionality. A description of the different story text formats is shown below:
Stories are well formed (they parse properly) and are formatted using paragraph tags. This is the only use of HTML tags in the stories I've seen. Unicode characters are inserted using HTML entities, e.g. the apostrophe is represented by ’.
<p>Bridget Milner wakes each morning whenever her two cats, Ninja and KitKat, begin meowing for their breakfast.</p>
<p>This fail-safe alarm helps bring the 87-year-old a measure of normalcy as she enters her ninth week of isolation in her one-bedroom apartment at
Vancouver’s Haro Park Centre, a 150-unit complex for seniors that has been battling an outbreak of COVID-19 that has so far killed 12 of her
fellow residents.</p>
<p>On Feb. 20, three weeks before the novel coronavirus was confirmed in the facility and residents were kept in their rooms, Ms. Milner’s
doctor told her to quarantine herself after she caught the seasonal flu.</p>
<p>Ms. Milner, like thousands of older Canadians who live in locked-down facilities, is trying her best to cope with her situation, but her
routine and her indomitable attitude could also uplift those isolating at home with a good deal more freedom.</p>
Story text is always wrapped in CDATA tags and is free of any HTML tags or entities. The only formatting used is the paragraph break, which is indicated by a vertical bar, '|', character (this will need to be replaced with a <p> tag).
<![CDATA[LeadHis parents were Russian spies whose international escapades became the fodder of an American television series.|On Thursday, Alexander
Vavilov was himself thrust into a real-life drama when he received news from the Supreme Court of Canada that will forever impact his future.|According
to the country's highest court, Canada cannot take away the citizenship of the 25-year-old Canadian-born man simply because his parents secretly worked
for their Russian masters.|"This decision is a vindication of all the time, resources and effort I have poured into my struggle," Vavilov said in a
statement. "It is recognition that not only do I feel Canadian, but I am Canadian in the eyes of the law."|Under Canada's immigration law, children born
here to "employees of a foreign government" are not eligible for citizenship by birth in the country. However, the court said that rule only applies to
those foreign employees with diplomatic protection and immunity rights. Spies don't enjoy those privileges.|]]>
Stories consist of complex code that can contain any HTML tag. This includes the frequent use of anchor and iframe tags. Each line of the story is contained in a paragraph tag with a num attribute that indicates the line number.
The code must have been produced by a Wysiwyg editor that doesn't enforce proper syntax. Thankfully browsers are forgiving, so if we choose to retain at least some of this formatting we won't have to fix every issue. I can't imagine the authors performing the HTML formatting manually (this could explain the poor syntax) but I could be wrong. This will be the most challenging format to sanitize. The POC for the newspaper service wraps these stories in CDATA tags so that the XML parser ignores the syntax errors.
<p num="0"><p>Thunder in the Valley has been cancelled for 2020. This time, it is due to the coronavirus pandemic and a B.C. ministerial order banning large gatherings this summer.</p>
</p><p num="1"><p>The Alberni Valley Drag Racing Association announced the cancellation on its website on Friday, April 24, 2020, following a Thursday night board meeting.</p>
</p><p num="2"><p><ins><a href="https://www.albernivalleynews.com/news/drag-racers-cancel-thunder-in-the-valley-for-2019/" target="_blank">READ: Drag racers cancel Thunder in the Valley for 2019</a></ins></p>
</p><p num="3"><p>"We basically came to the conclusion because of the coronavirus we weren't going to be able to race this year," AVDRA president Ben VeenKamp said.</p>
</p><p num="4"><p>This is the second year in a row that the popular drag racing event has been cancelled. The 2019 event was cancelled after the AVDRA and Alberni-Clayoquot Regional District were at odds over whether the races could return to the Alberni Valley Regional Airport, where the races had a successful run for more than a decade.</p>
</p><p num="5"><p>The City of Port Alberni had given permission for the race to run on Stamp Avenue in both 2019 and 2020, and with construction happening on San Group's plot of land at the corner of Roger Street and Stamp Avenue, new ideas for public parking were in the works for this year's event.</p>
Each story is preceded by a !@TEXT= delimiter and each subsequent paragraph is preceded by a vertical bar, '|', character. Each line of the story is terminated by a carriage return and two consecutive carriage returns indicate a paragraph break. The text contains no HTML tags or entities.
!@TEXT=For Vancouver author Iona Whishaw it's business as usual
during these pandemic times.
|"It's really not much of a different schedule from what I had
before," said Whishaw about staying home amid the COVID-19 crisis.
"For me, I have a daily writing habit and I do my daily writing
habit. That's all there is to it."
|Whishaw is the writer behind the successful Lane Winslow Mystery
novels. The seventh in the string of books - A Match Made for Murder
- was just released.
A publisher may include an article with the same id in several files. This will occur if the text of the article has been updated in some way and the new version of the article is sent in another file later in the day. None of the import formats used include a published time (only date) so the only way to tell which version of an article is the latest is from the order in which the files were received. The only exception to this relates to the Blacks News Group files, which include the time in the filename.
At the moment the POC for the newspaper service only sends an article to Kafka once. If there is already a content_reference record for the article it will be skipped, so only the most out-of-date article will be ingested. Three possible approaches to this might be:
- Keep only the first version of the article.
- If a new version of an existing article is received, update the existing article text with the new content.
- Add a new version of the article each time it is received.
I believe the existing system keeps all versions of each article, but we can confirm that at a later date.
It's been a couple of years since I worked on this, so the details are a little hazy, but I remember discovering some inconsistencies in the data sent by Blacks News Group and possibly MeltWater also. The one issue that comes to mind is that the value of the Papername field is not always the same for the same paper. There may be differences in the use of capitalization and white space etc., so we should be mindful of this.
Scott stressed how important the section element is to the usefulness of the news item. This is currently not being extracted.