Scope and Design
A number of requirements are dominating the actual scoping and fundamental design of saga-pilot. Those requirements are taken from (a) Radical input (see User Requirements), (b) from a set of target use cases (see below), (c) from experiences with BigJob and other pilot frameworks (also below), and (d) personal preferences (below, obviously).
- R-1: (x) scheduling in response to state changes, inspection (notifications, subscriptions)
- R-2: (x) handle jobs and data dependencies (mostly on TROY, but...)
- R-3: (-) bulk operations for performance
- R-4: (-) simple debugging / auditing / provenance (data streaming, online filter of streams)
- R-5: (x) implement P* semantics (PilotData, replication on demand)
- R-6: (-) stream stdout/stderr on CU level; retrieve partial output (callbacks)
- R-7: (-) handle communication / networking conditions in various DCIs (NATs, FWs, data push/pull, Laptop users)
- R-8: (x) pluggable schedulers (research)
- R-9: (-) perf: 10k concurrent CUs with 16 cores each, over 10 resources, in a single application (RepEx)
- R-10: (-) current BigJob use cases
- R-11: (x) backend for TROY (bundles...)
- R-12: (-) backend for gateways (multiple apps per overlay)
- R-13: (-) Replica Exchange (perf, scale (10k concurrent CUs a 16 cores))
- R-14: (x) data management is 1st order concern
- R-15: (-) focus on fail safety, reconnectability, inspection
- R-16: (-) support multiple agents (well defined agent interface)
- R-17: (-) handle NATs / Firewalls
- R-18: (-) secure communication and service endpoints
- R-19: (-) support for 3rd party transfer (Pilot API / DataPilot ...)
- R-20: (-) pilot framework not bound to application lifetime
- R-21: (-) errors percolate through the whole stack, up to the application
- R-22: (-) provide simple fail-safety measures (pilot dies - assign CUs to other pilot)
Legend for above entries:
- (-) : not strictly required for research
- (x) : strictly required for research
In a non SOA impl, we would:
- still need a dumb communication bridge (or only submit from head-nodes)
- have troubles to get notifications from pilot to app (in reasonable time)
SAGA-Pilot aims to be a pilot framework which
- S-1: implements the semantics of the pilot API (R-5, R-10..13),
- S-2: scales over multiple resources, many pilots and many many CUs/DUs (R-7, R-9, R-10, R-12, R-13, R-16, R-17),
-
S-3: can be used in heterogeneous and discontinuous environments
[1](R-7, R-10, R-12, R-17), - S-4: can handle multiple concurrent application instances (R-11, R-12),
- S-6: transparently handles data (R-2, R-10, R-14),
- S-7: is fully inspectable (R-1, R-4, R-6, R-12).
[1]: discontinuous environment: It can not be assumed that an application can always directly communicate with a pilot, and/or vice-versa.
Several requirements imply persistent state management, and continuous action thereupon:
-
R-1 - dynamic scheduling: scheduling can only be dynamic if it is based on dynamic data, which need to be available to the scheduler instance. Dynamic scheduling also only makes sense if it continues to adapt a schedule after the initial schedule was created, i.e. after point of submission (i.e. after submission script died).
-
R-2 - data dependencies: an active entity is needed to coordinate and initiate data staging on demand, even if the submission script is not active anymore. Pilot agents are not always able to perform that action, because of connectivity issues (behind NAT/firewall), security issues (missing credentials for pull), incomplete global knowledge (where is nearest replica, where lived the CU which produced the data).
-
R-4 - auditing/provenance: provenance information are relatively useless when they only exist in log files, at least for the currently active application instances.
-
S-4 - concurrent applications: scheduling of new (concurrent) workloads will need to evaluate previous (still active) workloads.
-
R-20 - fail safety: actions on failure require an active component that can timely evaluate state information.
-
R-5 - P* semantics includes early binding, i.e. the binding of a CU to a pilot agent which is not yet instantiated / alive. There is a need for an entity which can maintain information about that binding, to bridge the time between death of submission script and startup of the pilot.
Persistent state management can be had by dumb means such as centralized data file dumps, which are read and evaluated on each agent or user script activity. It can also be handled in a centralized data base (such as Redis does for BigJob) -- that database acts as a passive service, any actions on the data are performed by either running agents or currently active user scrips. Both of these solutions are not able to address
- timely staging of data on demand,
- timely reaction on failure condition, nor
- timely dynamic scheduling over multiple pilots.
Active service components which have access to backend state information can provide this functionality.
SAGA-Pilot will need to connect resource components which do not always support direct communication links (R-7, R-17) -- for example, agents will not be able to migrate CUs for dynamic, non-service based scheduling if no direct agent-to-agent communication is possible.
A service based approach will support such use cases. It will need to include bridging services (which bridge communication between NAT islands, for example).
(This is very similar to the state management discussion above, but relevant to a slightly different set of use cases.)
This capability will create variable flows of information from the backend to the scheduler and application level. If these information are not persistently stored (for example, because no consumer is alive), the information will be lost. This can be avoided by storing the information in log files, or a persistent data base -- however, they are then useless for dynamic use cases.
In other words, if neither scheduler nor application components have a persistent life time, they cannot dynamically react on notifications. In particular
On another note: full backend inspection and auditing can create very significant load, and significant data flows. Dynamic, on-the-fly filtering seems advisable for scalability.
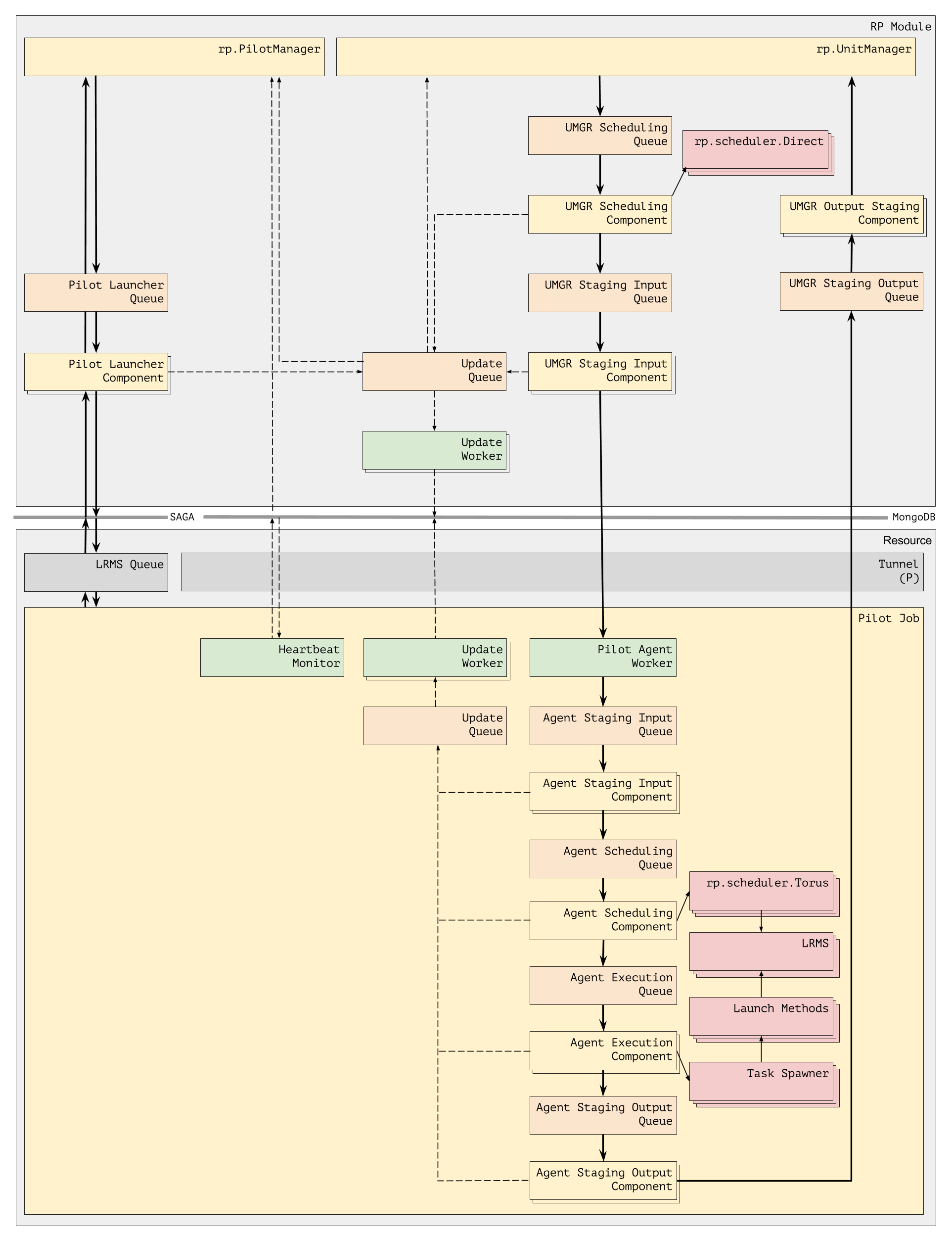
We distinguish 5 different types of services. Multiple instances may well be living within a single service container (i.e. within a single executable), so this separation is initially on a functional level:
- Pilot Manager: (Pilot Provisioner) creates pilots agents, based on submitted requests
- Unit Manager: (Workload Manager, aka Queue Manager, see below), manages submitted CUs and DUs
- Pilot Agent: manages a resource slice, executes CUs
- Information Service: manages notification, auditing, provenance; guides inspection
- Communication Bridge: supports pilot framework instances over discontinuous resources
Out of those components, the Pilot Manager has no actual need to be a service -- as SAGA-Pilot does not address complex pilot placement decisions, the Pilot Manager will not host a scheduler which could make dynamic use of persistent state information. However, the support for bulk and async operations may favor a service component for the pilot manager (see performance discussion below).
The Unit Manager will accommodate a (pluggable) scheduler component which at the same time consumes state, resource and framework state notifications for dynamically adaptive scheduling decisions. That scheduler can, in an initial implementation, be dumb -- but the Unit Manager will nevertheless need to maintain state of submitted, but not yet assigned CUs (to support early binding as per P*).
The Pilot Agent is the manager of the backend resource slice, which enacts the assigned CUs. Its lifetime is bound to the time of the backend resource acquisition.
The Information Service will filter, store, and route information about backend events. For the given set of use cases, a PubSub based implementation with a persistent database backend seems most suitable. This functionality could in principle be split and distributed over other service components -- i.e. one could add handling of pilot state events to the Pilot Manager, and of CU state events to the Unit Manager, etc -- but that would only complicate the architecture; would negate separation of concerns; would lead to inconsistent notification performances.
Communication Bridges will be needed to bridge communication islands -- for example to allow direct communication between components behind different NATs -- which is unfortunately frequently the case in our target environments. An initial implementation can be useful without bridges -- but the protocol design should include bridging from the beginning. We expect that communication bridges can almost always be integrated into other service components, to simplify framework bootstrapping.
Scheduling over a single pilot agent is relatively straight forward, and can mostly be performed within the pilot (not for early binding though). Our use cases, in particular for Troy, P* scope and BigJob scope, requires, however, that SAGA-Pilot can also scheduler over multiple pilots.
There are different ways conceivable to define over what set of pilots a specific CU can be scheduled, or, in other words, what set of pilots is managed by a specific scheduler. We propose to make that an explicit and obvious configuration issue, by introducing the notion of a queue.
A Queue is an entity to which CUs can be submitted; which has zero, one or multiple pilots associated; and which is managed by a single scheduler instance.
Zero pilots on a queue: CUs can be submitted before pilot creation requests are submitted.
Single pilot on Queue: represents direct binding of BigJob
Multiple Pilots on Queue: scheduler can perform (arbitrary simple / complex) operations to dynamically determine an optimal distribution of CUs over the associated pilots. It for example can inspect pilot load, and distribute based on that. It can distribute based on the CUs data dependencies, etc.
The submission of a CU to a Queue implies that the CU can run correctly on any of the associated pilots.
We feel that this additional abstraction has multiple immediate advantages:
- it explicitly and immediately supports different modes of CU-to-Pilot bindings (S-8)
- it provides a natural scope for the operation of a scheduler instance
- it allows the concurrent use of different schedulers (S-8)
- it makes the separation of user sessions simple (e.g., one queue per application instance) (S-8)
- it allows to use a specific pilot for multiple applications (S-4)
- it provides a natural scope for inter-CU dependencies
- it makes difficult concepts easy to expose to the application level (binding, scheduler scope, CU state, application session).
For those reasons, we intent to actually render the Unit Manager as Queue Manager.
There are different metrics to SAGA-Pilot scalability. We consider the most important ones (in decreasing order of importance):
- number of CUs concurrently managed / concurrently executed
- number of resources concurrently managed
- time for CU submission
- queueing and scheduling overhead for CUs
- time for pilot submission
- frequency and timeliness of notifications
We are not overly concerned about the first two metrics, as we feel they in itself do not pose high demands, and can be handled by carefully crafted pilot agents (good experiences exist). Both metrics will, however, but more reliably be sustained by a service backed architecture, as both are volatile to state losses and connectivity problems.
Time for cu submission, pilot submission and notification delays are mostly determined by network latencies (given a not too stupid protocol), and are thus subject to the usual optimizations: bulk operations, and async operations. We consider the support of both optimizations as crucial for the overall framework performance, and they need to be supported on fundamental level. In particular async operations are also relevant for the notification semantics.
Queuing and scheduling overhead is considered to be a performance artefact of the queue scheduler and the pilot agent -- and are thus subject to the specific implementations of these (pluggable) components.
Due keep this document short (ha!), we did not discuss several other issues we feel are supportive of the presented SOA architecture. In particular:
- the support of user communities
- the support of long running application sessions
- the support of security mechanisms (key registries; reconnecting to sessions)
- the support of CU dependencies, also for CUs which have already finished
- several of the requirements listed above...
- several of the requirements listed above...
The discussion above woefully ignored several security considerations -- those will be discussed in a different document.